计算机理论¶
待复习的内容¶
- xarges命令
linux¶
- linux的文件属性的第一位是文件类型(文档、目录、或者链接),后面每三位为一组,第一组是所有者权限,第二组是与所有者同一用户组的用户的权限,第三组是与所有者非同一用户组的用户的权限
- chmod命令
- linux当中的命令是什么?
(1)一个可执行程序(2)一个内建于shell自身的命令(3)一个shell函数,即小规模的shell脚本,也是在环境变量里面的(4)一个命令的别名
- whereis命令的效率是来自于linux自动创建并每天更新的一个数据库,而这个数据库每天才更新一次,所以会导致刚添加的文件可能用wehereis搜索不到
- locate命令与whereis非常相似,且它们使用相同的数据库,但是locate命令可以搜索所有的文件,能够用一些匹配语法,使用updatedb命令可以手动更新数据库
- find命令可以使用-exec选项来对这些文件执行单个命令,-exec选项需要以
;结尾,中间的{}是一个占位符,要想执行多个命令可以将命令写入到shell脚本当中 - 关于xarges命令的作用:可以从标准输入中接受输入,并转化为一个特定的参数列表,因为有些命令不能从标准输入当中获取参数(比如哪些呢?这个我还有点疑问,以及背后的原理又是什么呢?)
- 关于shell脚本的非原子性,今天实验了一下,如果后面的语句有问题,前面的语句也会被执行成功,非原子性应该是普遍存在的,似乎解释性语言的单个命令就是一个原子性操作,如果要实现整体的原子性可能要用加锁什么的
- 符号链接的用途,用一个符号链接来一个经常变动版本的文件,然后程序要引用文件的时候就只需要引用这个符号链接,万一文件的版本发生变动,就只需要修改这个链接,而不是到引用过这个文件的地方将所有的文件名都修改一遍。还有另外一种用途就是在nginx的配置当中学到的将项目的配置链接到nginx的配置文件夹当中去
- 除了rm命令外的大多数文件操作针对的都是符号链接的对象而非符号链接本身
- 使用alias可以创建和查看命令的别名,理解基本命令后利用这个功能可以大幅度提升自己的效率,当然前提是对所建立别名的命令已经用得滚瓜烂熟了,陌生的还是不要用,影响理解
- 使用<这个符号可以重定向标准输入,比如默认的标准输入来源是键盘,通过
<file命令可以将标准输入来源重定向到文件,这个东西用起来和pipe差不多,还是有很多命令不支持标准输入(其背后肯定有某种机制存在)
[me@linuxbox ~]$ cat < lazy_dog.txt The quick brown fox jumped over the lazy dog.在这段命令当中cat读取一个文件并复制到标准输出,当cat没有参数的时候,其默认输入来自标准输入,而通过<重定向标准输入可以使其输入来自于一个文件,效果与直接以文件作为参数是等同的
- shell会对输入的字符进行处理,这个过程叫做“展开”
- linux当中所有系统环境变量其实和shell环境变量是一回事情,环境变量分为系统级和用户级,系统级
/etc/profile&etc/bash.bashrc&etc/environment,而用户级则在家目录下的~/.bash_profile&~/.bashrc - 创建的文件默认没有执行权限,创建的目录默认三项权限都有,文件与目录的权限如:
| 属性 | 文件 | 目录 |
|---|---|---|
| r(4) | 允许打开并读取文件内容 | 允许列出目录中的内容,前提是目录必须设置了可执行属性(x) |
| w(2) | 允许写入文件内容, 但是不 允许对文件进行重命名或删除 | 允许在目录下新建、删除或重命名文件,前提是目录必须设置了可执行属性(x) |
| x(1) | 允许将文件作为程序来执行, 使用脚本语言编写的程序必须 设置为可读才能被执行 | 允许进入目录 |
理解一下目录的权限吧,x(1)是最基本的权限,然后r(4)其次,w(2)最末,所以一般是744或者755在上一层目录删除其中的文件夹的时候,如果没有对本文件夹的w权限且文件夹中还有文件,会发现根本删不掉对于没有执行权限的目录,其下的所有内容都无法打开了对于有执行权限没有读取权限的目录,只是无法读取目录中的内容,里面的文件还是可以打开的对于没有读取权限的目录,无法删除,因为删除的时候要读取目录下的所有文件
- shell在shell会话中存储了大量的信息,而这些信息被称为shell的环境,shell环境中有两种基本的信息,一种是环境变量(针对系统而言),另外一种是shell变量(针对shell而言),环境变量都是大写字母,除了变量,shell环境中还存储了shell函数和别名
- 环境变量并不直接存储在启动文件当中,需要使用export命令来进行设置
- usr/bin下安装的是系统自带的应用,而usr/local/bin下安装的是用户自己安装的应用
- 包管理工具分为两种,底层工具和上层工具,比如dpkg和apt-get,前者可以用来安装软件安装包
- linux的设备都是挂在在一个统一的文件系统树当中,有些是实体设备,有些是虚拟设备,不同的设备下有不同的文件系统类型,linux本地的文件系统是ext3
- git文件状态的变化
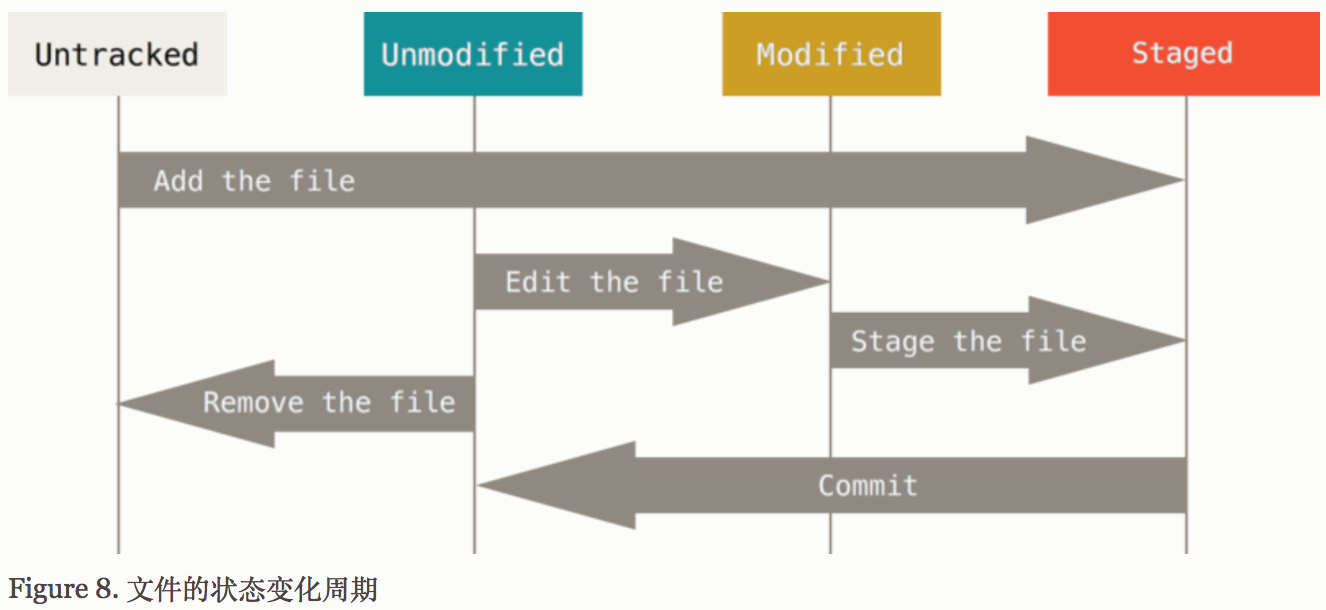 在这里git add有两种作用,一种是将untracked的文件变为tracked&staged,另外一种是将modified的文件变为staged
在这里git add有两种作用,一种是将untracked的文件变为tracked&staged,另外一种是将modified的文件变为staged
- 对于我而言的git使用方法:
(1)要加文件的时候使用git add,平时都用都用git commit -a,坏处是大批量加文件的时候很麻烦(2)用.gitignore来忽略文件,平时都用git add .和git commit,有点繁琐,而且有时候可能忘记将文件加入忽略还是有后面这种方法更加合适一些
- git move相当于
$ mv README.md README $ git rm README.md $ git add README
- 什么是文件句柄

- zip命令一定要进入到你要压缩的那个目录进行压缩,不然会包含整个路径
- nginx会依次加载配置,中间有配置加载没成功会导致后面的配置无法加载
计算机¶
- 字符编码:现在计算机中在用的一般都是Unicode编码(内存当中使用的),有一部分可能遗留的是ASCII编码,而在输出和写入的时候一般都是用UTF-8编码。这么理解的话,UTF-8在表层使用的,而Unicode编码则是在底层使用的。(这里所说的Unicode其实是一种UTF-16之类的东西,可能的原因是因为定长,更加方便吧)为什么会这样呢?
可以简单地参考一下 这个
- 原子性:一个操作要么完整地被执行,要么就完全不执行,这种特性就叫原子性
- 关于编码:unicode是一种抽象的东西,具体存储到计算机里面需要一种编码方式,最好采用的编码方式是utf-8,python2默认的编码方式是ascii(可能因为这种编码方式占用的存储空间比较少),如果在python当中选择了ascii作为编码方式,那么输入中文字符会导致无法存储,因为输入的字符串是unicode,而unicode实际存储的时候发现用ascii存储不了,我用python解释器实践了一下
u'学习'.encode("ASCII"),发现UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128),这里的原因就是unicode作为一种抽象,当要被代码使用的时候(这种抽象的东西怎么样的形式存在的呢?unicode在python中怎么存在的?应该就是直接存储为unicode值,界面上是通过unicode值解析出来的,但是编码其实就是要转成二进制),解释器会对其进行编码,而默认的编码形式不支持某些unicode值,就会报错。 - 二进制文件与文本文件没有本质的区别,最大的区别就在于打开这些文件的程序对他们的解释结果上,文本文件会最终解释为文本,利用各种编码方式进行解释,而二进制文件则会解释为其他内容,从更深的层次上,文本文件比所谓的二进制文件少了一部分控制信息
注解
以读文件为例,实际上是磁盘 》》 文件缓冲区》》应用程序内存空间 这两个转化过程。我们说“文本文件和二进制文件没有区别”,实际上针对的是第一个过程;既然没有区别,那么打开方式不同,为何显示内容就不同呢?这个区别实际上是第二个过程造成的。文件实际上包括两部分,控制信息和内容信息。纯文本文件仅仅是没有控制格式信息罢了;实际上也是一种特殊的二进制文件。所以,我们很难区分二者的不同,因为他们的概念上不是完全互斥的。
- 当应用之间需要传递字符串的时候,只用字符串就可以解决问题,但如果要传递对象(一种特殊的数据结构),则需要使用到json,在python当中,dict对象能够直接被序列化(将内存中的数据转化为一种可存储可传输的格式)为json,而其他对象则需要事先进行一定的操作,一般的序列化操作使用pickle即可,支持更多的类型
- 网络层的防火墙(iptables)可以视为一种ip封包过滤器,运作在底层的TCP/IP协议堆栈上,但是iptables drop掉的包,tcpdump也是可以抓到的,相当于tcpdump也是非常底层的,其运作不受iptables的影响,而阿里云的安全组规则应该直接在主机之外就把包给过滤掉了,tcpdump会受到其影响
- 关于守护线程,守护线程存在的意义是为用户线程提供服务,因此如果所有用户线程结束的话,进程会结束,正在运行的守护线程也会终止
- 掩码是一串二进制代码对目标字段进行位运算,具体的不用管了,了解一下就好
- 原来GUI就是一个循环的消息模型,主线程不断处理消息队列,当遇到问题导致处理时间过长的时候由于消息队列里不断累积未处理的消息感觉看上去像是死机了,通过消息模型可以实现异步IO
- 子程序(函数)的调用是通过栈实现的,层级调用,不断向顶层堆积,到顶后不断返回
- 协程是在一个线程当中执行一个函数(实际上应该是协程)中途中断,转而去执行另外一个函数,函数是协程的一种特例(顺序执行),协程在python当中通过yield来实现
- 为什么要定义栈这么一个数据结构呢?其最大的好处是具有记忆性
注解
堆栈的最重要的特点其实就是具有“记忆”性。至于这样有什么好处,可不是用一两句话就能说得清楚的。下面我给一个例子,大致说明堆栈的记忆特点:表达式的处理。 所谓表达式的处理,其实就是:“接受用户所写的一串字符串,其实是一个表达式,由数、运算符(包含括号)组成,要求计算这个表达式的结果”。例如,输入为3+5*4^1(3加5乘以4的1次方)计算结果应该是23(地球人都知道),但是这是计算机程序的处理结果,包括要发现可能性的输入错误。 这里牵扯所谓的运算优先级的问题,而能让先出现的优先级较低的运算符,能在“以后”运算,就得靠栈。 比如上例,如果用栈处理运算符,那么初始栈为空,然后先遇到“+”,入栈后,“+”在栈底; 当遇到`*`时,再入栈,那么栈底为“+”,栈顶为`*`,以后出栈的顺序就是先“*”后“+”,即先做乘法,再做加法。 这只是一个简单的说法,表达式的处理远比这复杂,但方法的核心就是“堆栈”。 大概明吧了吧,路漫漫其修远兮!尔会上下而求索乎?
- 关于foreign key,foreign key的约束是为了保证数据一致性,如果一个表的主键作为其他表的外键,那么不能在外键对应数据仍存在的情况下,改动这个主键。互联网行业的话基本不用外键了,因为性能太差,不过还是要了解一下。
- 加盐加密是一种对系统登录口令的加密方式,它实现的方式是将每一个口令同一个叫做”盐“(salt)的n位随机数相关联
- 序列化(Serialization)将对象的状态信息转换为可以存储或传输的形式的过程
- 标准IO的缓冲机制一共有三种,分别为:
(1)行缓冲:在缓冲区中遇到换行符n或者r(mac os X实测两种都会)的时候执行IO操作(2)全缓冲:填满IO缓冲区的时候才执行IO操作(3)无缓冲:不进行缓冲对于python而言可以调用sys.stdout.flush()强制执行IO操作,实际上sys.stdout是一个io.TextIOWrapper对象
- 光栅图像:也叫做位图、点阵图、像素图,简单的说,就是最小单位由像素构成的图,只有点的信息,缩放时会失真
- 关于纯文本(文本文件)的定义:狭义上来说是只由特定编码标准序列组成的计算机编码文本,不含有任何结构化信息,从这个层面上来看,html这种就不属于纯文本,而广义上来看,每个字节都是文本字符的就属于纯文本,从这个层面上来看,html这种属于纯文本
- 计算机当中操作的最小单位可以视为字节,所以以后二进制数据全部可以当做字节流来看。看了一下,字是存储器当中的最小单元,在计算机当中指令什么的都是以字为单位进行传输的,比如64位处理器的话一个指定就是64位*感觉这块的知识还要好好补一补,可以通过看以前的书和笔记回顾一下,找一个连接点连接起来*
- 动态作用域:函数调用所在的环境计算自由变量。词法作用域:根据定义函数的环境计算自由变量。
- OOP是数据结构优先于算法,是组织数据优先于操作数据
- 面向对象感觉更加结构化,使用全局变量最令人不安的就是所有的全局变量在那里,究竟哪些函数要用到哪些,很容易混乱不清,而面向对象能对这些变量做更好的管理
- 依赖就是一个类的方法会操纵另一个类,比如一个frame当中的按钮会打开另外一个frame,应当将这种依赖降至最小,甚至可以为了降低耦合在聚合对象当中进行调用,而非类之间直接的依赖模式
- 之前的vocabulary类和那些Frame类之间应该称之为聚合关系
- 线程池的目的感觉就是为了控制线程的数量啊
- 硬编码:指将可变变量用一个固定值来代替的方法。用这种方法编译后,如果以后需要更改此变量就非常困难了。
- json当中的数据类型
(1)对象数据类型:用嵌套来表示,大括号中的字段就是这个对象所拥有的属性(键不一定在js当中貌似并不一定要使用字符串,不过我这边就直接使用字符串就行)(2)字符串类型:双引号包裹就是字符串(3)数字类型:包括整型、浮点数和定点数(这个是什么鬼)(4)布尔类型:true和false(5)null类型:null(6)数组类型:两个中括号json在html发送过程当中应该就是以文本的方式进行存储的(也就是通过ASCII编码可以解析),但json只是一种数据格式,是json对象的文本表示方法,并不是说js当中的对象是以文本形式存储的,两者有本质区别
- 静态类型指的是编译器在compile time执行类型检查,动态类型指的是编译器(虚拟机)在runtime执行类型检查。简单地说,在声明了一个变量之后,不能改变它的类型的语言,是静态语言;能够随时改变它的类型的语言,是动态语言。因为动态语言的特性,一般需要运行时虚拟机支持。https://www.zhihu.com/question/19918532/answer/13568542
- 所谓图灵完备,是说一个机器(概念上的)或者一门语言,能够计算一切可计算的问题,通俗说,就是和图灵机等价,也就是通用计算机,从这个角度说,我们可以很简单的判断一个语言是否图灵完备,只要看它能不能模拟图灵机就行了,而要模拟图灵机,无非就是支持循环、分支、数组、运算之类的,这基本上是个语言就支持了,反过来,由于现在的计算机的计算能力不能超越图灵机,所以两者是全等的,然后还可以推出,图灵完备的语言都是等价的
- 关于语言理论概念的一篇好文:http://blog.csdn.net/xtlisk/article/details/39091705
- 静态语言是可以通过抽象接口实现鸭子类型的
- 所谓动态性就是把编译器做的事情,放在运行期做,实现更强的灵活性
- 方法的编译时绑定叫做前期绑定,运行时绑定叫做后期绑定,java支持多态,在这个层面上肯定是有后期绑定的
- 由于python的动态性,写代码比写xml配置要更加简便
- UTC相当于本初子午线(即经度0度)上的平均太阳时,过去曾用格林威治平均时(GMT)来表示。这两者几乎是同一概念。它们都是指的格林尼治标准时间,只不过UTC的称呼更为正式一点。两者的区别在于前者是一个天文上的概念,而后者是基于一个原子钟。
- 向内存中写入就是输入流,从内存中写出就是输出流,写过java的通过序列化和反序列化来深拷贝对象就可以很轻松地理解这一点了
- 鲁棒是Robust的音译,也就是健壮和强壮的意思
- Windows 里说的「ANSI」其实是 Windows code pages,这个模式根据当前 locale 选定具体的编码,比如简中 locale 下是 GBK。把自己这些 code page 称作「ANSI」是 Windows 的臭毛病。在 ASCII 范围内它们应该是和 ASCII 一致的。
- 关于线程的知识,值得一看。http://blog.csdn.net/weiweicao0429/article/details/53185999
- 缓存存在的目的就是为了解决快慢双方之间的交互问题,如果要从快的输入到慢的,那么缓存提供临时存储,慢慢输给慢的(感觉这个就像是消息队列的作用),如果要从慢的输入到快的,缓存之前先存一些,快的可以先直接从缓存中拿,数据库查询很慢,服务器response很快,那么缓存中先存一些用来response
- 关于远古时期打印机慢导致电脑跟着等的问题,意识这个就是一个IO问题,如何解决呢?
(1)异步IO,发完消息不等回调就去做别的(2)多任务(多进程多线程)(3)打印机缓存(电脑内存空间当中的)
- 为什么要先卸载设备再移除设备呢?因为数据可能还在从缓存中写入设备,这时移除可能导致数据丢失,但是u盘的传输貌似不是这样,其中还是有一定区别的,u盘那个可能是为了防止当前存在数据交互吧,但肯定不是从缓存当中写入的,因为没有那么快
- 注意字的长度和处理器位数是一致,而一个字节则是8位
- 递归的本质就是压栈,如果是尾递归的话可以很方便地改写为一个循环
架构抽象¶
- 非侵入式设计:从框架角度可以这样理解,无需继承框架提供的类,这种设计就可以看作是非侵入式设计,如果继承了这些框架类,就是侵入设计,如果以后想更换框架,之前写过的代码几乎无法重用,如果非侵入式设计则之前写过的代码仍然可以继续使用。
- 关于IOC的一些思考。
感觉ioc就是注册机制,将原先强耦合的东西解耦开来,原先是顶层决定底层,自上而下的依赖关系,而控制反转之后就是通过底层去构建顶层,先把底层的造出来,塞进(注入)到要构建的上层类中去在python当中就是注册机制了,比如我写的空战游戏,舰艇类是通过注册(注入)的方式组装起来的,而非写死在类中。spring所做的事情就是要注册进行的东西都自动生成了,通过id与实体类的映射关系,ioc容器给你创建完然后注册进去这个其实和我写的魔塔游戏很相似,通过一个映射的map来存储类与建构方式的关系,然后通过一个工具函数(相当于ioc控制器)来将map中的东西一一创建出来并注册进tower对象当中实际上或许我也可以给我的魔塔小游戏写一个简单的ioc工具,说实话,为什么python当中就不提ioc呢?哎反正说白了,控制反转就是从强耦合变为注册制,xml配置文件就连接了虚位以待id和要注册进去的类。我们的项目算是比较死了,真正灵活的代码可以通过替换映射来控制你注册进去的究竟是什么东西。感觉好处可以分为注册的好处与映射的好处,注册使得关系解耦,如果不是注册则需要去修改类的代码,而且由于顶层控制底层,如果你要去为底层增加一个功能,你需要从顶层把这个传下去,而使用注册制之后你只需要在底层做改变就可以,不需要进行一步步地传导(感觉很像函数包裹)映射的好处是把注册的配置独立出来,不需要去进行繁琐的注册,新建对象,而是通过一个控制器根据配置来进行注册,比如说flask可以实现一个配置文件,将要插入的组件放在配置文件中,然后由一个工具函数把它们注册进去,对于多层的复杂结构这种控制是很有必要的可以这样看,一个是一体车,一个是组装车,一体车的话顶层需要决定怎么构造底层,而组装车的话是所有组件构造好了组装起来的。对了 控制容器的还有一个好处是根据依赖自动组装,因为有时候层数多了注册也是很麻烦的。而IoC Container在进行这个工作的时候是反过来的,它先从最上层开始往下找依赖关系,到达最底层之后再往上一步一步new(有点像深度优先遍历)(这句话说得很形象)flask的组件为什么要注册制呢?因为这是可插拔可替换的。如果你写死了,那么你的插拔就要通过改内部代码去做,而且由内部类去创建的话万一有多种创建方式呢,又要层层传递,最终导致顶层需要无数参数来进行控制,毫无必要。就像你要一辆车你可以有两种选择,一种是将需求从头到尾描述一遍,而另外一种则是将一系列的组件选好,再拼装起来。前者如果你要改你的需要,比如新增一个需求,那你就要深入修改内部,而后者你只需要修改其中一个组件就可以了。从便利性和看着爽的角度上来说,注册制都要远远优于一体化。一体化感觉上一般只适合单层强关系,如果你的类的成员变量也是一个自定义对象的话,那么这个成员变量就不适合内部来创建,而更适合通过注册来赋予。我觉得,依赖倒置不应该是低层依赖高层。而是低层和高层都依赖接口。这样可以很好的解耦。(这句话是对的。一体化模式和除了依赖接口,还依赖底层(因为你直接控制了底层的构架),而组件化模式是只依赖接口,你底层的东西只要能实现接口就行了,我不管你怎么创建。)总结一下:控制反转前:上层控制下层的构建,上层需要调用下层的接口,上层依赖下层控制反转后:上层不控制下层的构建,只需要调用下层的接口,那么其实相当于分离了,因为只需要对接口负责即可依赖倒置的定义:High level modules should not depend upon low level modules. Both should depend upon abstractions. Abstractions should not depend upon details. Details should depend upon abstractions.感觉现在对于spring的核心内容已经有了一定的理解了,看问题更加通透,以后写复杂的代码也能规避一些坑了。将对象创建过程从编译时延期到运行时,即通过配置进行加载(这句话要想想,难道平时编译过程当中就创建对象了么??)
3. python的依赖注入,有意思了。https://www.cnblogs.com/xinsiwei18/p/5937952.html 4.
加密用途总结¶
加密分为对称加密和非对称加密,接下来分别总结一下对称加密和非对称加密的用途
一,非对称加密(公钥和私钥)¶
- ssh连接,服务器拿客户端的公钥验证客户端身份(私钥加密的东西通过公钥可以解密,持有私钥者一般是需要被识别身份的一方)
- https的连接(这个具体还要再研究一下)
二,对称加密¶
- 服务端分发的token,服务端通过密钥产生一个token分发给客户端,客户端带着这个token来访问服务器,服务器通过密钥解密这个token可以获得token当中客户端的身份信息,甚至还能获取token过期时间(场景为邮箱验证,所以不能直接发密钥,总不能让用户来进行加密吧)(PS.这个其实客户端也根本没有加密解密的过程,不过是分发一个token而已,服务端对一些信息的确有加解密)
- api访问身份验证,这个不是通过token的形式,而是通过直接分发密钥的形式,客户端通过密钥对信息进行加密(产生的信息相当于token,分发的密钥可以是有时限的),服务端通过密钥进行解密,这样服务端就能够识别客户端的身份(由于用户是开发者,而且请求十分频繁,因此可以采用给用户密钥让用户加密这种更加安全的方式)(PS.这个其实不能算加密吧,毕竟信息内容其实是暴露的,而且根本没有解密过程,只是通过md5的手段生成一个哈希值,保证请求是请求者发出,也能够阻止重放攻击)
- 加密通讯,双方保存密钥进行发出信息进行加密,接受信息进行解密(https当中的通讯方式)
- 前两种都没有对请求信息进行加密,主要是用来验证用户身份,说明互联网上的安全问题其一是出在身份伪造上,其二是出在通讯信息被窃取上