python学习¶
注意事项¶
- 关于super函数的用法
def method(self, arg): super().method(arg) # This does the same thing as: # super(C, self).method(arg)
- 此类错误的原因是这个函数应当有两个参数(会在被调用的时候被传递),但是我只定义了一个
TypeError: validate_email() takes 1 positional argument but 2 were given
- 用读模式打开文件的话如果文件不存在会raise FileNotFoundError
- python当中对于类进行实例化的本质其实是调用
__new__方法之后再调用__init__方法,所以在方法当中实例化自身的类是没有任何问题的,不会产生无限循环上的问题 - 所有的中缀运算符原则上都返回一个新对象,而增量赋值表达式(比如+=和*=之类的),有可能会修改第一个操作数
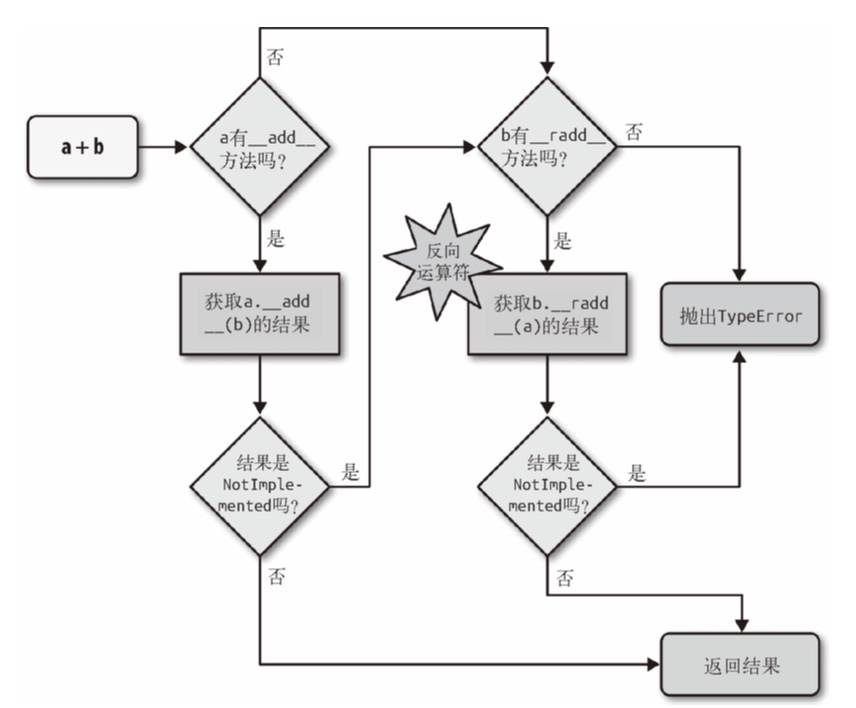
- 中缀运算符的底层逻辑:
(1)radd是用来在左操作数没有add方法的时候调用右操作数的radd方法来作为后备的,由于是右操作数,所以要指明r,不然像str的相加会乱掉(2)对于==和!=来说,如果反向调用失败(也就是双方都没有这个就会比较id,所以+不完全等价于add就像for不完全等价于iter,所以对于自定义对象的比较是通过比较id进行的
- 在python社区当中,大多数时候把迭代器和生成器视作同一概念,对我来说就把生成器看做是一种特殊的迭代器就行了
- reprlib.repr是用于生成大型数据结构的简略字符串表示形式
- 关于可迭代对象

- iter函数其实是调用对象的iter方法,生成一个迭代器而已,并不是将当前对象转换为迭代器,和list()这种还是有区别的
- 这句话很有意思,由于迭代器需要维护当前的状态,所以需要一个单独的对象去做,而非自己就是一个迭代器

- python构建迭代器往往是通过生成器函数,因为如果是手动构建类的话感觉还是可能无法达到节省内存的目的
- 只要一个函数的定义体当中有yield关键字,就是一个生成器函数,调用生成器函数会返回一个生成器对象
- 生成器中用return的话会抛出stopiteration异常
- 生成器表达式只是生成器函数的一个语法糖,可以用来代替生成器函数
- 通过yield from能够产出另外一个生成器当中的值,在这里调用者相当于一个中介
- 归约函数就是接受一个可迭代对象,返回一个值
- seed() 方法改变随机数生成器的种子,可以在调用其他随机模块函数之前调用此函数
- try finally可以用于流程控制,即便try里面return甚至是sys.exit,finally也会调用。其通常用于释放重要的资源(网络连接、文件连接)或者还原临时变更的状态
- 文件的enter方法返回的是self,所以as后面的是获取enter方法的返回对象
21. with块和循环块不会定义新的作用域,在里面定义的内容外部依旧可用,会定义新作用域的有:函数、方法、类、生成器表达式、列表推导式
23. 上下文管理器中的exit当中为什么需要异常参数呢?其实感觉是代替了excpet的作用,不仅作为finaly还能捕获异常,两全其美啊。而原来 try finally 当中finally也可以通过调用sys.exc_info来获取这三个参数
24. 可以使用contextmanager将简单的生成器构建为上下文管理器,在使用contextmanager装饰器的时候要把yield语句放在try finally语句当中,不然如果出现异常会导致异常无法处理。因为contextmanager构造的exit方法如果接受到异常参数会自动抛出异常,而抛出异常使用的是throw方法,进入到协程领域了
25. yield from主要作用于嵌套生成器
26. 关于协程
(1)当用作协程时 yield会在表达式当中使用(2)通过send方法可以开启暂停的协程,其参数会成为yield表达式的值(3)使用协程总是要通过next方法来激活协程,或者通过.send(None)也是一样的效果(4)协程返回值是通过stopiteration异常返回的,要通过读取异常的value才能获取返回值(5)为什么yield from教程当中要有委派生成器呢?因为一个协程只能用一次,所以需要每次调用的时候都实例化一个子生成器来进行处理(6)yield from的作用就是调用一个可迭代对象,这个对象可以是生成器,因此也可以是协程(7)yield from还可以接受send过来的值 传递给调用的协程,因此使用yield from的协程很适合用来做委派器(8)可以理解send和yield from都是将变量插入到协程的定义域,只不过yield from所使用的变量是来自send的(9)委派生成器的作用相当于管道(10)协程可以用来管理并发活动,因为可以在多个协程当中进行切换,这个并发系统是基于事件的,每执行完一个事件就返回主循环寻找下一个事件
- future类的实例都表示可能已经完成或者尚未完成的延迟计算
- 期物封装待完成的操作,感觉上相当于是封装任务的完成状态
- 对于CPU密集工作,python需要使用多进程的解决方案
- 真正的并行肯定是要用到多核的,所以python只能通过多进程实现并行
31. python当中数据属性和方法统称为属性,方法只是可以调用的属性(其实本质上是一个属性property)
33. 异常处理还是条件判断的选择首要因素是是否直观,比如first(),如果没有值明显返回为None,这个直接用if判断很清晰,如果用异常的话判断TypeError很奇怪,最好判断的异常是语句操作的典型异常直观异常,否则会很奇怪
34. init方法不是真正的构造方法,真正的构造方法是new,其会返回一个实例对象并将该对象传递给init方法的self参数,所以init所做的工作其实是初始化 Foo(‘bar’)=Foo.new(‘bar’) ,如果返回的是该类的实例才会调用init方法
35. 对于实例属性查询的顺序:
(1)如果attr是一个Python自动产生的属性,找到!(优先级非常高!(2)查找obj.class.dict,如果attr存在并且是data descriptor(也就是所谓的覆盖型descriptor,有__set__方法的),返回data descriptor的get方法的结果,如果没有继续在obj.class的父类以及祖先类中寻找data descriptor(3)在obj.dict中查找,这一步分两种情况,第一种情况是obj是一个普通实例,找到就直接返回,找不到进行下一步。第二种情况是obj是一个类,依次在obj和它的父类、祖先类的dict中查找,如果找到一个descriptor就返回descriptor的get方法的结果,否则直接返回attr。如果没有找到,进行下一步。(4)在obj.class.dict中查找,如果找到了一个descriptor(插一句:这里的descriptor一定是non-data descriptor,如果它是data descriptor,第二步就找到它了)descriptor的get方法的结果。如果找到一个普通属性,直接返回属性值。如果没找到,进行下一步(5)Defaulting to getattr()(6)raise AttributeError
- 对于读写都关闭的使用_前缀,对于读开写闭或者读闭写开的使用property,对于都开的使用一般类属性或者一般实例属性
- 工厂函数和构造方法的选择,前者灵活,后者简单
- 所有的函数都是有get方法的,用对象来读取才会被使用get方法,并且返回一个绑定了一定对象在第一个参数的“方法”对象(那么能够直接对类调用实例方法并且传入一个self参数么)
39. 特殊方法只会在类当中寻找 41. 元类就是type,因为元类作为一种对象也是一种类的实例,这个类就是元类 42. 修正一个误区:wraps装饰器装饰的函数似乎并非一定要return,只是没有return的话这个函数本身就不会返回任何东西,如果用来wrap视图函数那肯定是不可以的 43. 编码解码操作都应当放在程序出入口进行,即请求一来立即解码,要写二进制文件的时候才进行编码 44. python3用w写文件会默认encoding=utf-8,所以必须传入write str才行 45. 警告!!!不要使用str()对bytes进行转换,因为str只是显示bytes的字面量,要使用decode才行
new_token = user.token_generate() view_return = func(*args, **kwargs) return_json = json.loads(view_return[0]) # 警告!!!不要使用str()对bytes进行转换,因为str只是显示bytes的字面量,要使用decode才行 return_json['new_token'] = new_token.decode('utf-8') return json.dumps(return_json), view_return[1], view_return[2]
- 关于什么是pathlike object
注解
path-like object An object representing a file system path. A path-like object is either a str or bytes object representing a path, or an object implementing the os.PathLike protocol. An object that supports the os.PathLike protocol can be converted to a str or bytes file system path by calling the os.fspath() function; os.fsdecode() and os.fsencode() can be used to guarantee a str or bytes result instead, respectively. Introduced by PEP 519.
这里说明path-like object其实是个str或者bytes或者任何遵循了os.PathLike protocol的对象,后者是实现了__fspath__()方法的对象,这个方法要求返回一个str或者是bytes,可以想象其作用原理应该是先检验是否是str or bytes,不是的话查看其是否有这个方法
- 通过一个例子来讲解一下os.path.dirname() os.path.abspath()的机制
首先问题源于这段在flaskPractice02当中产出覆盖测试报告的代码# 下面都是为了print出coverage报告的绝对路径 print('Coverage Summary:') basedir = os.path.abspath(os.path.dirname(__file__)) covdir = os.path.join(basedir, 'tmp/coverage') COV.html_report(directory=covdir) print('HTML version: file://{}/index.html'.format(covdir)) COV.erase()这里有一个问题是besedir这个语句为什么这么写先来看这段代码import os print(1) print(__file__) print(type(__file__)) print(2) print(os.path.dirname(__file__)) print(type(os.path.dirname(__file__))) print(3) print(os.path.abspath(os.path.dirname(__file__))) print(os.path.abspath(''))最终结果如下1 test.py <class 'str'> 2 <class 'str'> 3 /Users/caolei/flaskLearning/flaskPractice02 /Users/caolei/flaskLearning/flaskPractice02 python test.py 0.03s user 0.01s system 68% cpu 0.062 total这就说明了几个问题:(1)首先__file__这个东西是一个字符串,其值取决于你是从哪里调用,如果你是从外部导入(非main),那么这个值就是一个绝对路径,如果你是从直接运行该模块,其值就是相对于你运行环境的一个相对路径(比如你在a/下运行a/b/c.py,那么c.py的__file__返回的就是b/c.py(2)os.path.dirname的用途是对于一个path-like进行处理,返回一个去除了当前文件夹的字符串,比如对于a/b/c.py返回的就是a/b(3)os.path.abspath根据文档几乎等效于normpath(join(os.getcwd(), path)),看得出来是怎么回事了,他获取的前置路径不是模块所处的路径,而是main所处的路径综上所述路径的获取取决于这个文件是否是main,如果不是的话,那么你使用__file__还是什么的获取的是绝对路径,如果是的话__file__获取的就是调用者的路径(调用main者)。使用os.path.abspath()获取的永远是是调用者的路径(调用main者)那么basedir = os.path.abspath(os.path.dirname(__file__))这个的目的就是获取file的当前目录了,因为无论你在哪个层级调用,__file__总是会产生一个相对于你运行环境的路径,要通过os.path.abspath来拼接转化为绝对路径,所以不管怎么样最终的目的都是绝对路径化。太精妙了!不管从哪里导入os.path.abspath永远能和__file__衔接上,因为导入的本质就是就是运行,只不过是以绝对路径的形式上面为什么import的时候会变成绝对路径呢?应该是因为import本身就是通过绝对路径import的,这个和import的机制有关
- sys模块主要是用于提供与系统环境相关的操作,而os模块则是文件目录相关的操作
- 其实模块层面也是有闭包的啊,闭包归根结底是词法作用域,也就是函数会根据定义函数的环境计算自由变量,但是在python的定义当中确实说闭包的引用的自由变量必须是非全局变量,也是,既然是全部变量那就没必要作为自由变量了,所以姑且还是认为闭包只存在于函数当中
- 所以由上面这个问题延伸出来函数保存状态的另一种方式就是使用全局变量
- __getattr__方法会在没找到实例属性的时候被调用,而__getattribute__会在每次访问实例属性的时候都被调用
- __setattr__方法会在每次赋值的时候被调用,不管是使用直接赋值还是内置的setattr函数,都会被调用
- 释放GIL:同一时间只能运行一段python代码,但是如果GIL释放的话,一个核中可以等待sock.recv()的返回,另一个核中可以执行其他代码
- epoll是select模块的改进
OS将I/O状态的变化都封装成了事件,如可读事件、可写事件。并且提供了专门的系统模块让应用程序可以接收事件通知。这个模块就是select。让应用程序可以通过select注册文件描述符和回调函数。当文件描述符的状态发生变化时,select就调用事先注册的回调函数。
- EVENT_READ是socket中的内容到了一定量就变成可读的了,而这个量是接收低水位,默认值是1
- 调用多个函数,其自由变量是函数自身维护的,不会改变
…: a = 2 …: def boo(): …: print(a) …: return boo …: In [2]: a = foo() In [3]: b = foo() In [4]: a Out[4]: .boo> In [5]: b Out[5]: .boo> In [6]: a is b Out[6]: False In [7]: a == b Out[7]: False
- 闭包创建的时候本身就是通过函数调用返回的,其就是一个独立的东西,而你在模块当中引用全局变量所有的操作都是在模块下的,定义域也是模块的,并不独立
- 启动协程不仅可以使用next,还可以使用send(None),两者的效果是一致的
- 很多类都会在init的时候进行一些初始化,即使这些类的构造方法不接受参数,那么就不能贸然继承,必须在继承的时候super一下超类的构造函数
60. 使用os.path.join去合并路径,这样就能在不同的系统下生成对应格式的路径,能够有更加强大的兼容性 2. dict构造函数还是挺有用的
[dict(title=result.title, body=result.body, img=result.img, gmt_create=result.gmt_create ) for result in results]有一点要注意,在这个构造函数当中,虽然没有对键定义类型,但是 其实默认的类型就是str
- 使用
else: continue break来跳出多重循环,相当于没结果的话continue继续进行前面一层循环,有结果的话break到前面一层循环的结束位置
补充一点:
for else语法要结合break来使用,也就是break的话不会执行else中的内容,所以上文中如果子循环体内break的话就会跳过else,然后break,如果子循环体内没有break的话就会直接else中的continue,继续执行循环
- 可以使用python3原生的pyvenv来代替virtualenv,不过我的系统版本是2.7,暂时还是先不搞吧
- 对于字典尽量使用get,这样如果没有这个key就会返回None,避免异常的出现。好方法,可以用if判断来取代之前的defaultdict进行单词计数,不然的话还要用异常处理(get还有更多设置default,挺好用的)
- 通过
?可以将* +这些操作符从贪婪模式改为非贪婪模式 - 可以使用enumerate()函数来获取sequence的索引和值(参数并不一定是sequece,所有iterable都可以的,因为从原理是来看enumerate是迭代一个给一个索引值,但是对于字典这种没有什么意义,因为索引值是不存在的)
- 使用dict.items()可以将key和value以元组的形式返回
- 引用包下的模块可以使用
from .views import views_blueprint,但是不知道怎么回事直接import.views是无效的。可能是.只能用在from语句中,可以尝试from . import views这里的.就是当前目录的意思 - 使用
pip freeze > requirements.txt可以生成需求文档 - 使用
pip install -r requirements.txt可以安装所有的依赖包 - PyCharm的环境变量是自行设置的,因此.zshrc中export的环境变量对于pycharm是无效的
- 使用生成器能够节省内存(并不总是能,要看具体的实现原理,如果不能的话那就没什么意义)
- 在拆包的时候使用_占位符可以摒弃不需要的元组元素
- 现在有了一个更好的方法来代替defaultdict类和dict.get方法来设置默认的字典值,就是对一个字典使用dict.setdefault(key, default),若没有key则将key和对应的default放进去(主要是针对通过查找来插入值这样的需求,如统计单词数,使用还是比较局限的)
- map和reduce这样的高阶函数可以用列表推导或者生成器表达式来进行代替
- 写workflow可以通过raise异常来进行测试
- 可以通过hasattr函数来判断对象是否含有某个属性(这个值得一用)
- 可以使用
python -c来直接执行python命令,中间用分号隔开就行 - 使用
os.remove可以删除文件 - python会使用特殊的规则来比较两个元组,先比较下标0的然后依次递增下标,这个特性在使用sort方法进行排序的时候很有用
- 关于python的import机制:所有的路径都是根据sys.path来的,而执行程序的时候相当于将该文件的存储路径加入到了sys.path当中,所有的import都是在sys.path当中的路径中去寻找的,这样就可以完全说通了,而且整体而言非常清晰
笔记¶
- try finally 一般用于释放外部资源之类的场景(文件或者网络连接),可以使用上下文管理器代替
- 现在想来有点理解对象的含义了,之前像string类型的函数调用也有了概念,'xxx'作为一个string类的实例化对象,其自然可以调用string类的方法
- 命令行下运行python解释器的时候,也是以当前目录为依据的,因此能够import当前目录下的文件,其实是模块的命名空间中有一个叫做__file__的变量,存储了这个模块的路径,import的时候就可以根据这个路径去搜索
- 关于Collections模块:其提供了一些数据结构
(1)Counter:dict的子类,其实就是一个字典,如果将hashable对象导入其中,hashable对象的元素为字典的键,其计数为字典的值(学了散列表现在理解为什么要hashable了吧)(2)defaultdict:dict的子类,其第一个参数能够为字典设定默认的值数据类型
- 关于python迭代器:需要支持两种方法,__iter__返回自身,__next__返回迭代器的下一个值,如果没有下一个值可以返回,那么应该抛出StopIteration异常。迭代器一般有两个基本参数,低值和高值。由此可以总结一下:iterable有两种,第一种是实现__iter__的,iterator是其中的一种特例,其都是靠返回的iterator中的next方法实现迭代,第二种则是实现__getitem__的,这个有一些下标规则
- 关于python生成器:生成器用于更简单地创建一个迭代器,用生成器表达式的确可以更简单地创建迭代器,因为一般的迭代器还是很难搞的,用yield语句来进行创建,生成器可以节约内存
究竟什么是生成器呢?
注解
generator iterator An object created by a generator function. Each yield temporarily suspends processing, remembering the location execution state (including local variables and pending try-statements). When the generator iterator resumes, it picks-up where it left-off (in contrast to functions which start fresh on every invocation).
根据官方文档,要区分生成器函数(generator function)和生成器(generator iterator),生成器是由生成器函数创建的一个迭代器,所以生成器算是迭代器的子集
- 关于python生成器表达式:一个简单的生成器表达式的例子
sum(x*x for x in range(1, 10)) - 关于闭包:由另外一个函数返回的函数,也就是嵌套在里面的那个函数(暂时搞不明白是干嘛用的),真正的定义应该是指延伸了作用于的函数,其中包含函数定义体当中的引用、但是不在定义体当中定义的 非全局变量 ,注意这里是非全局,因此只能套在函数当中用
source def add_number(num): def adder(number): return num + number return adder >>> a_10 = add_number(10) >>> a_10(21) 31
- 关于装饰器:用来给一些对象添加新的行为
- 关于unittest的使用,主要有两个点:
(1)unittest.main的作用注解
unittest.main():使用她可以方便的将一个单元测试模块变为可直接运行的测试脚本,main()方法使用TestLoader类来搜索所有包含在该模块中以“test”命名开头的测试方法,并自动执行他们。执行方法的默认顺序是:根据ASCII码的顺序加载测试用例,数字与字母的顺序为:0-9,A-Z,a-z。所以以A开头的测试用例方法会优先执行,以a开头会后执行。
(2)unittest.TestCase的作用:用来定义其子类
- 关于项目结构
(1)模块当中需要一个__init__.py文件(2)项目中需要一个MANIFEST.in文件,用来在使用sdist命令时找出将成为项目源代码一部分的所有文件(3)项目中需要一个setup.py,用来创建源代码压缩包或安装软件
- 关于
*的使用:*后面列表元组都可以使用,加上就相当于给该元组或列表解包,从这个角度上来说可变参数*args,这里的args相当于一个sequence对象,而**args中的args则相当于是一个mapping(映射)对象 - 关于变量,要记住python的变量只是像指针一样指向数据,而不是说变量就是数据
比如说
a = 'ABC' b = a a = 'XYZ' print(b)这时输出的其实是'ABC',因为 b = a 这个操作其实是将b这个变量指向了a这个变量指向的数据
- 关于字典的原理,其实就是使用散列表,因此字典的好处在于性能高,劣处在于占用的内存大,是一种用空间来换取时间的方法
- 在python当中,函数也是一个对象,因此如果在一个类中加入__call__方法,就可以将该类的实例当做函数用,这也是为什么会出现
DBSession = sessionmaker(bind=engine) session = DBSession()这样的对象使用情况
- 异常可以用在判断函数的参数是否符合标准上,这样就提供了一个完美的接口,廖雪峰关于函数的这个讲得挺有意思的,对于参数类型的判断可以使用
isinstance()函数 - 定义函数默认参数的时候注意一个重点,就是函数的默认参数必须是不可变对象,因为在定义函数的时候会直接计算出参数的值(实参?),而可变对象的值有可能随着不断地调用而发生改变,这是一个很重要的坑
- 定义函数的时候可以定义可变参数,也就是
*parameter,函数内部其实就是把接受进来的参数视为一个tuple整体,所以仅仅是调用的时候方便一些,不用转成tuple传进去 - 关键字参数的作用是将传进来的参数集合组装成一个dict,也可以直接将传进来的dict进行拷贝,用途就是接受一些带有参数关键字的参数,这样就能对传进来的参数进行区分
- python函数中参数定义的顺序:必选参数、默认参数、可变参数、命名关键字参数、关键字参数,其中必选参数和默认参数可以合称为位置参数
- 还有个神奇的技巧,对于任意函数,都可以通过
func(*arg, **kw)的形式来进行调用,这是一个什么样的过程呢?相当于定义函数的时候*的作用是将这个区间进来的参数合成一个tuple,而调用函数的时候*的作用则是说明后面带的是一个tuple,并将这个tuple进行分解从而导入到参数表当中去。妙处在于传递进函数的变量必须保证不赋值的在前,赋值的在后,这就使得这种转换成为可能,就算你的函数用了全组合参数照样可以这样干,组合参数这样设计是有道理的,非命名的在前命名的在后,如果用了可变参数你的默认参数也必须声明。还有一个点,非命名在前和命名在后与不同类型参数的排列的是相分离的,两者不能合并起来看 - 可以通过translate方法来对字符串进行处理,去除其中包含的某些字符,实际应用比如说是给一篇英文文章去除标点符号等,还有一点就是由于英文书写逗号句号之类的标点符号后面都是要带空格的,因此通过translate来处理不会出现单词拼接的情况,但是如果只是去除标点的话会漏掉回车换行符,所以更加高级的用法是re.sub函数,这个比较牛逼,正则表达式中
\W就可以代表所有非字母数字的符号,而\d可以代表所有数字 - 函数内部如果尝试去应该说是为全局变量赋值,就是屏蔽这个全局变量,从而创造出一个与全局变量同名的局部变量
- 只要对类中的属性(变量)加上
__,就会成为私有变量,外部不能进行访问,用私有变量加类方法的方式可以检查传入值,保证入口的安全性,不过这个不能访问并非真的不能,特殊手段还是可以访问的,不过没必要知道 - 多态的意义,可以先简单理解为支持方法重载
对扩展开放:允许新增Animal子类;对修改封闭:不需要修改依赖Animal类型的run_twice()等函数。
- python当中许多函数接受的参数是 实现了某个方法的所有类型 ,而非某个特定类型。
因为函数内部只是调用了这个对象的某个方法,并没有使用isinstance对该对象进行检验,这个坏处就是你还要说明你这个参数是需要支持哪些方法的参数,虽然宽松但可能会很乱
这就是动态语言的“鸭子类型”,它并不要求严格的继承体系,一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子。
Python的“file-like object“就是一种鸭子类型。对真正的文件对象,它有一个read()方法,返回其内容。但是,许多对象,只要有read()方法,都被视为“file-like object“。许多函数接收的参数就是“file-like object“,你不一定要传入真正的文件对象,完全可以传入任何实现了read()方法的对象。
- 实例属性与类属性不是同一个概念,前者是__init__方法中定义的,后者是在和所有类方法同一个层面定义的
- 函数名其实也是一个变量,指向的对象是那个函数,只是函数这种对象有“调用”这个能力,本质上是实现了__call__方法
- for循环对于实现了__iter__方法的对象,通过调用__iter__方法返回一个iterator对象,然后对该对象使用__next__方法,而对于没有实现__iter__方法的对象则是通过下标实现的
- 关于编码方式的理解:尝试了一下在shell中print一个中文字符串,发现能print出来不会乱码,可能的原因是shell默认的编码是utf8,能够显示出来,也有可能是python读取到了输出环境的编码格式变量,所以用utf8的形式输出,但是在脚本当中
在python2当中,顶部的注释只能表明读取方式而已,python解释器当中的似乎还是会使用ascii编码,python3当中就转换成了utf-8
对于python来说,输入的文本反正就是按照ascii来进行解码(如果不定义解码模式的话),然后其中如果有unicode字符串就把ascii转换成unicode(utf-16),对字符串进行某些操作的时候直接将ascii字节流转换成字符流(unicode),print的时候不管是啥,都先转成默认编码进行输出。还有一个问题,如何解释我今天写translate脚本的时候解决的那个bug呢?(python2这部分比较乱,就不再深入了,主要是和python解释器内置编码有关系,暂时不用python2先不管)
- python的很多异常都是内置的函数抛出来的,但应该也有一部分是来自于解释器,比如一些语法错误之类的
- 在python调用的层层嵌套当中,底层可以尝试去捕捉异常,但很多时候捕捉到异常只是记录一下又提交这个异常,让顶层调用者去处理这个异常,而不是自己就处理掉,这样的写法对于提高函数的复用性作用很大
- 用print去解bug的方式效率太低,很多地方可以采用assert关键字进行替代,启动python解释器的时候可以使用-o参数来关闭assert,更高级的方式是使用logging,用pdb也是可行的,不过很低效,最好还是用ide来进行调试,终极武器是logging
- 单元测试的好处是测试自动化,不用修改代码后反复地去进行测试,尤其适合大型代码,那些个中逻辑非常复杂的,还有一个好处是将来重构代码的时候可以直接用上,还需要考虑一下如何设计函数使得重构之后无需修改测试
- 还有一种是文档测试,也挺有用的,之后可以尝试一下
- python3里面默认编码就是utf8,而且str貌似就是unicode字符串,而和python2中的string相同的则是str encode之后的bytes,也就是说python3里面应该是没有必要用到unicode相关的东西,反正默认的str就是unicode
- 重申一下,python当中的所谓文件名就是一个pathlike的string,并非真的是当前文件的名称,如果只写当前文件的名称,那么只能找到本目录下的文件(实际上pathlike的定义就是一个string或者bytes或者支持某种方法的对象)
- 关于python当中的类变量和实例变量,类变量是实例共享的,是实例创建之前就存在的,而实例变量是实例私有的,是实例创建的时候才具备的,当一个对象的实例变量和类变量相同的时候,对于实例来说它的类变量就无法调用,因为实例变量会被优先调用
- python当中的类继承,如果你不定义init方法的话,会直接继承父类的init方法,而如果你定义了init方法的话,则可以调用父类的构造方法,把参数传进去
- 所谓回调就是定义一个函数,系统运行的时候会通过一个中间函数去调用这个函数,这个函数就是回调函数
- 关于闭包,闭包就是一个能返回内部定义的函数的函数,其好处在于返回的函数能够在内部存储外部函数的变量,这样在其调用的时候能够直接根据这些变量得到结果,要注意不要在外部变量中用循环来生成函数元组,由于变量会定位最终值,所以取出来的函数所引用到的迭代变量都是一样的,这个其实是因为函数存储的自由变量是自由变量本身而不是自由变量的别名,这个和函数参数不同
- python的base64模块用来将二进制数据以三字节转换为文本数据四字节从而通过文本来传输二进制数据,在某些诸如url的地方可以用到。之所以要这样做是因为http协议当中对于url只能使用ascii编码,而二进制数据有很多ascii编码没有对应字符的值,所以需要用base64进行转码
- hashlib模块提供哈希算法(MD5是其中一种),可以将任意长度的字符串转化为一个长度固定的数据串,可以用于查看他人是否有修改数据,有个很神奇的应用,只要在数据库中保存密码的hash值而非密码明文,就可以防止密码被盗的风险(散列表的散列所运用的就是哈希算法)
- contextlib中@contextmanager装饰器能够结合一个生成器构造一个上下文管理器
看了下源码,还是通过一个上下文类去解决的,只是一个语法糖而已,enter的时候调用一下next,执行yield之前的部分,exit的时候调用一下next,执行yield之后的部分
- python当中使用链接的时候不要使用
~来代表家目录,会读不出来 - for else语句相当于for执行完会执行else,搭配break可以跳出else语句
- 切片操作取前不取后,和range函数是一样的
- 几种概念的区分:
(1)Iterable:可以直接作用于for循环,实现了__iter__或者__getitem__方法的所有对象,sequence数据类型都是可以的,看了下dict发现原来是有iter方法的,相当于是中iterable mapping,这样来看内置类型似乎都是通过__iter__方法来实现迭代的啊,应该是这样效率更高节省内存吧(2)Iterator:可以被next()函数调用并不断返回下一个值的对象,是Iterable的子集,相当于实现__next__方法的对象,iterator是一种特例,其__iter__方法返回自身(3)Generator:是Iterator的子集,即通过生成器表达式或者生成器函数生成的iterator
- 交互解释器是调用repr()函数来显示对象
- 关于python的特殊方法 Python类中的特殊方法 - 老鸟菜了 - 博客园
说说几种非常常用的,使用特殊方法是维持python语言一致性的一个很好的方式
(1)``__init__`` 这个就不解释了,创建对象的时候返回的时候被调用(2)``__str__`` print和使用str()的时候被调用(3)``__getitem__`` 使用x[y]操作的时候被调用(4)``__len__`` 使用len()的时候被调用(5)``__repr__`` 使用repr或者在shell中输入的时候被调用(6)``__getattr__`` 和__setattr__使用obj.attr的时候会被call(7)``__contains__`` 使用in的时候被call,没有则使用下标,a in b相当于b.__contains__(a)(8)``__iter__`` 使用for循环的时候被call,没有则使用下标(9)``__slot__`` 定义类中可以被外界访问的属性,用来节省内存
- 为什么python当中会存在所谓的鸭子类型呢?因为python中的内置函数不对传入参数的类型进行检验,所以你传入的参数只要支持了某在在函数内会被调用的方法就能够使用,这也就导致了python当中有什么callable,Iterable之类的提法,这些东西其实是对所有实现了某些方法的对象的总称
53. 本来有个疑问,对于reversed这个函数应当是序列(supports the sequence protocol)才能传入其中,那么什么是sequence protocol呢?看了下文档发现应该是实现了__len__和__getitem__方法,并且后者的参数必须能从0开始且为整数 55. 关于iterable对象在doc当中有一个很明确的解释
注解
An object capable of returning its members one at a time. Examples of iterables include all sequence types (such as list, str, and tuple) and some non-sequence types like dict, file objects, and objects of any classes you define with an __iter__() or __getitem__() method. Iterables can be used in a for loop and in many other places where a sequence is needed (zip(), map(), ...). When an iterable object is passed as an argument to the built-in function iter(), it returns an iterator for the object. This iterator is good for one pass over the set of values. When using iterables, it is usually not necessary to call iter() or deal with iterator objects yourself. The for statement does that automatically for you, creating a temporary unnamed variable to hold the iterator for the duration of the loop. See also iterator, sequence, and generator.
首先iterable是包含sequence,并且包含所有实现了__iter__或者__getitem__方法的对象,这样的话有一个问题, 内置类型本质上和鸭子类型一样么?他们都有共同的xx方法么? 基本一样,但是有点区别,内置类型的话会有一些更加底层的途径来支持,但还是有这个方法
所以实际上iterable等同于所有实现了__iter__或者__getitem__的对象,也就等价于可以使用for循环的对象
- __iter__方法是使用for循环的时候使用iterator,那么为什么没有__iter__方法也能使用for循环呢?这是因为有__getitem__存在,这种情况下会使用下标的方式进行迭代,这样的话dict应该使用的是前者,因为dict并没有从0开始依次递增的下标(dict如果没有实现__iter__方法的话应该会报异常)
- 命名关键字参数相当于一定要你指明关键词来传,是一定要有的,并非和关键字参数一样可有可无
- 在python3中,对于object类的继承是隐式的
- 何谓元编程?怎么理解元编程? - 知乎
注解
不过 metaprogramming 更狭义的意思应该是指「编写能改变语言语法特性或者运行时特性的程序」。换言之,一种语言本来做不到的事情,通过你编程来修改它,使得它可以做到了,这就是元编程。
- 如果一个对象没有__str__方法,而解释器又想进行调用的时候,会使用__repr__作为代替
- 中缀运算符的基本原则就是不改变操作对象(注意+=不是中缀操作符)
- bool()函数的背后会call __bool__方法,如果没有__bool__方法,则会call __len__方法
- 为什么要用特殊方法?主要是为了让python的内置数据类型走后门,通过一些底层的方式来进行处理,从而提高运算效率,另一方面,还可以简化语言,并且让自定义类能够使用这些方法。可以将这些看起来是函数的东西看做是某种一元运算符。
- 生成一个特定对象的函数都可以成为工厂函数,当然有些可能是类对象伪装的
- python当中不可变对象仅有内置类型当中的那几个(数字、字符串和元组),其他都是可变的,所以不要被不可变误导了,自定义对象都是可变对象,都能在外部对内部进行操作。不可变对象其实是把对于对象属性的修改功能都屏蔽了
- enumerate函数可以对所有的iterable对象使用,可以对字典使用enumerate,对于映射类型迭代的是键(set相当于没有值纯键)
- 一段很有趣的测试代码:
In [11]: class Test: ...: _dict = {0: 0, 1: 1, 'x': 'x', 2: 2, 4: 4} ...: _dict2 = [0, 1, 2] ...: def __getitem__(self, key): ...: return self._dict2[key] ...: test = Test() ...: for index, value in enumerate([1, 2, 3]): ...: print(index) ...: for index, value in enumerate(test): ...: print(index) ...: 0 1 2 0 1 2之前我在__getitem__当中直接print了,导致出现了
0 0 null 1 1 null这样的结果, 原因是enumerate会去调用__getitem__并且返回下标和对应的值(因为没有实现__iter__方法)
- 关于回调函数,相当于是系统层和应用层之间(或者两个高度抽象的层级之间)通过中间函数(起始函数)进行对于双方的调用,可以是系统层传一个回调函数给应用层,应用层进行调用,也可以是应用层传一个回调函数给系统层,系统层进行调用。中间函数相当于调用方暴露的一个接口,用来接受它想要调用的回调函数
- 关于装饰器,这个要结合闭包的概念来看,其实可以直接将
@decorate def foo(): pass中的@decorate看做是
foo = decorate(foo)如果是@decorate(arg)则可以看做是
foo = decorate(arg)(foo)示例代码看`这里 <https://www.zhihu.com/collection/170894537>`_
def log(func): def wrapper(*arg, **kw): print('Start {}'.format(func)) return func(*arg, **kw) return wrapper相当于是将foo这个变量指向了wrapper这个对象
- python内置的sequence可以分为两种:
(1)容器序列:存放不同值( -实质上存放的是对值的引用-::也不一定完全是对值的引用:: ),list,tuple,collections.deque(2)扁平序列:存放相同值(实质上存放的就是值),str,bytes,还有一些乱七八糟的根据是否可以修改也可以分为两种:
(1)可变:list以及一些乱七八糟的(2)不可变:tuple,str和bytes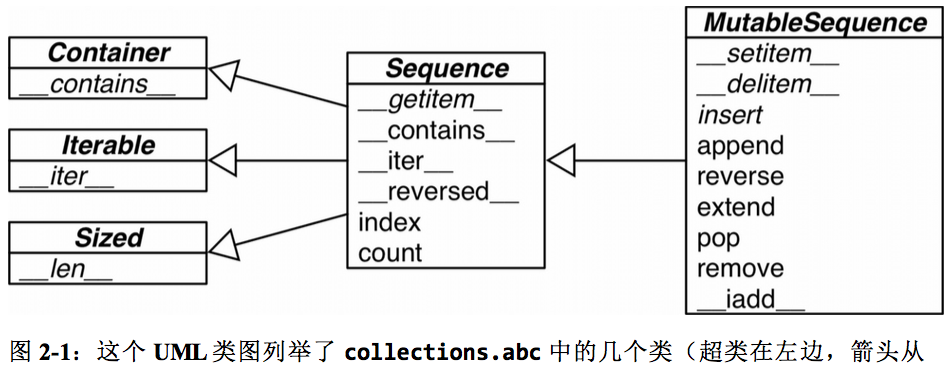
- 列表推导式、生成器表达式等都有自己的局部作用域,可以放心享用。而普通的for循环没有
- 直接import和from import造成的效果是一致的,都执行模块整个模块
- property是一个类,foo这里就直接作为fget的值传了进去,相当于这个类有一个类变量foo,这是一个property实例,fget操控的是对于foo的读取,fset操控的是对foo的写入。如何操控呢?其中的重点是通过接受的这些函数重载__get__等方法,这样在使用object.foo的时候返回的就是__get__方法中的return,使用object.foo = x的时候返回的就是__set__方法中的return,这些方法只有以.被调用的时候才会使用,如果直接取这个对象,那还是对象本身,默认的__get__方法其实应该是返回自身。另外,使用@foo.setter,其实相当于foo2=foo.setter(foo2),中间发生的其实是返回一个重载了__set__方法的property对象,相当于给原有的对象换了一下__set__方法而已
property装饰器的作用是可以对一个属性的三大方法进行重载,可以用一个类变量去代理对实例变量的操作,并可以做一些限制,比如不能读取不能写入什么的
注意这个是__get__而非__getattr__方法,前者是只有对于类的dict中获取的属性(类变量)才会调用(看看有没有),后者是获取对象(不管类还是实例)属性的时候都会调用
补充,如果只有__get__没有__set__那么就无法修改这个类属性(也可以称为descriper对象,property装饰器的作用就是将一个类对象变为descriper对象)
再说一点,property是有默认的__set__方法的,这样才能报异常,不然赋值就被实例对象覆盖掉了
- 不止是元组可以用来拆包,所有可迭代对象均可以用来拆包,经过实验无论是被拆方还是接受方都可以是可迭代对象,只要数量一致就可以了
- namedtuple工厂函数返回一个类对象,然后把它赋值给Card变量,这里为什么不能直接用类名来初始化对象而要用变量名呢?感觉因为类名并非一个实体,其实做class声明的时候应该是class a相当于a = class_generate(“a”),其实类名也是类的一个属性,类名和引用该类的对象的名称是可以不一样的,这个涉及到内省

- python的风格是在切片和区间范围中不包含最后一个元素,这样做有利于直观地了解所包含的元素数量,直接两个值相减就可以了
- 切片操作
a:b:c相当于slice(a, b, c),返回一个切片对象 - 在对序列使用
*号的时候要当心,如果是这个序列里有可变变量,那么将产生n个对同一可变对象的引用

- 原来之前的想法都是错误的,通过实例给类变量赋值并不能改变其他实例以及抽象类的类变量
python的类变量与实例变量以及__dict__属性 - 蔚蓝行 - 博客园
通过上面这篇文章,可以发现对于实例无论怎么操作都只会改变实例的__dict__属性,而不会改变类的dict,因此对于实例的改变不会影响到类,更不会影响到其他实例,对于类的改变却会影响到所有的实例,只是有时候这个影响会被实例自身的所覆盖
+=和*=优先使用__iadd__方法, 其次使用__add__方法- 一个很有趣的现象

从中得出的教训:
(1)不要把可变对象放在元组里,会导致意想不到的错误(2)增量赋值不是一个原子操作
- 使用array可以代替列表存储大量的数字,因为array(只能用来存储数字)所存储的不是对象而是字节表述,array使用类型码进行创建
- 使用deque(双向队列)对于频繁的先进先出操作是一个更好的选择
- 使用set对于频繁的包含操作是一个更好的选择
- 对于sequence类型的精确释义
注解
An iterable which supports efficient element access using integer indices via the __getitem__() special method and defines a __len__() method that returns the length of the sequence. Some built-in sequence types are list, str, tuple, and bytes. Note that dict also supports __getitem__() and __len__(), but is considered a mapping rather than a sequence because the lookups use arbitrary immutable keys rather than integers.
The collections.abc.Sequence abstract base class defines a much richer interface that goes beyond just __getitem__() and __len__(), adding count(), index(), __contains__(), and __reversed__(). Types that implement this expanded interface can be registered explicitly using register().
- 关于python的命名空间 Python命名空间的本质 - windlaughing - 博客园
- 在函数内使用外部变量的时候切记要使用global,不然万一不小心对这个变量使用了赋值,会发现你并没有修改全局变量
- 上下文管理器指的是那些实现了__enter__和__exit__方法的对象,比如open的使用方法
with open(‘filename’, ‘r’) as f相当于
f = open('filename', 'r').__enter__() try... finaly: open('filename', 'r').__exit__()由于open是一个函数对象(实例)而非类,因此要将
open(’filename‘,’r’)看作是一个整体也就是一个文件对象,反正不管怎么样with obj as f就是要f = obj.__enter__(),然后try语句块,最后obj.__exit__()
- 关于什么时候用类 Python 中使用类的最佳时刻是什么? - V2EX
注解
两个以上的函数,之间有数据共享,就应该使用类来封装;借用《C++深思录》中一句话,用类来表示概念。
- python多线程的线程安全有两层含义,第一层是多核CPU,会同时运行两个线程有可能造成单变量同时被使用,这个有一个什么全局锁之类的解决,在单核下虽然分片运行,还是会有问题,需要使用Lock。第二层是不同线程使用的数据会互相污染,其实也就是要线程隔离,flask的local_stack就是为了解决这个问题
- python的GIL就是一把全局排他锁 Python的GIL是什么鬼,多线程性能究竟如何 • cenalulu’s Tech Blog
注解
每一个interpreter进程,只能同时仅有一个线程来执行, 获得相关的锁, 存取相关的资源.
相当于即使是多核效率也跟单核一样
- 实例变量是实例构建的时候才产生的变量,而类变量是类定义的时候就存在的变量
- 关于python的命名空间 Python命名空间的本质 - windlaughing - 博客园
几个要点:
(1)使用globals()可以访问模块的命名空间(2)from module import和import module之间的不同:注解
使用import module,模块自身被导入,但是它保持着自已的名字空间,这就是为什么您需要使用模块名来访问它的函数或属性:module.function 的原因。 但是使用 from module import function,实际上是从另一个模块中将指定的函数和属性导入到您自己的名字空间,这就是为什么您可以直接访问它们却不需要引用它们所来源的模块
- 要区分请求命名和对象,python的赋值不会复制数据,而是将命名绑定到对象,del也只是在局部作用于删除命名
- 类方法、实例方法和静态方法
(1)类方法:类和实例都能调用,第一个参数必须是类,会把调用者的类传进去(2)实例方法:实例才能调用,第一个参数必须是对象(3)静态方法:没有参数要求
- 泛映射类型的定义:
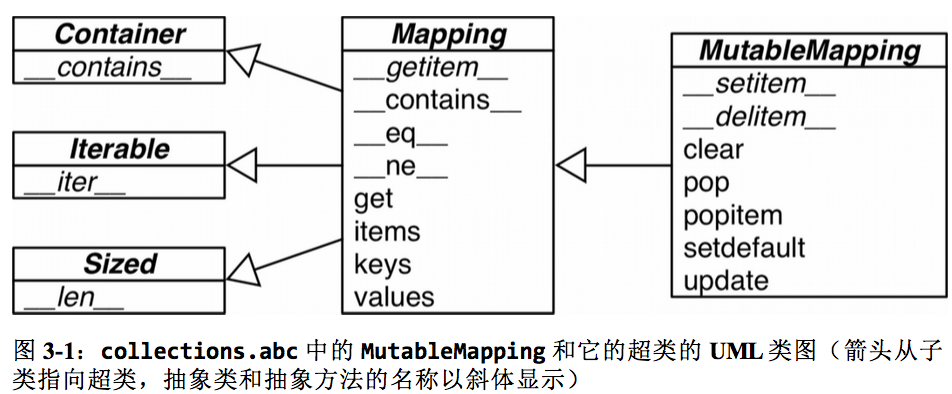
这里的mapping就是映射的意思
抽象基类一般不会被用来直接继承,作用主要是“映射类型”的形式化的文档,标准库当中的
标准库当中的所有映射类型都是通过dict来实现的,因此要求所有的键都是可散列的
- 可散列的定义:
注解
如果一个对象是可散列的,那么这个对象的生命周期当中,他的散列值是不变的,并且需要实现__hash__和__eq__方法,如果两个可散列对象是相等的,那么它们的散列值一定是一样的
可散列类型包括 原子不可变 类型(str、bytes和数值类型),如果一个元组包含的对象都是可散列的,那么这个元组也是可散列的。 要注意可散列不等于不可变
- 几种常见的字典构造方式:
(1)dict()工厂函数,可以传递的参数类型包括关键字参数或者一个包含键值对形式的可迭代对象(2)使用{}(3)字典推导
- 抽象基类只是定义一些规范,里面没有对应的方法实现(都是纯虚函数)
- 集合类型的定义:
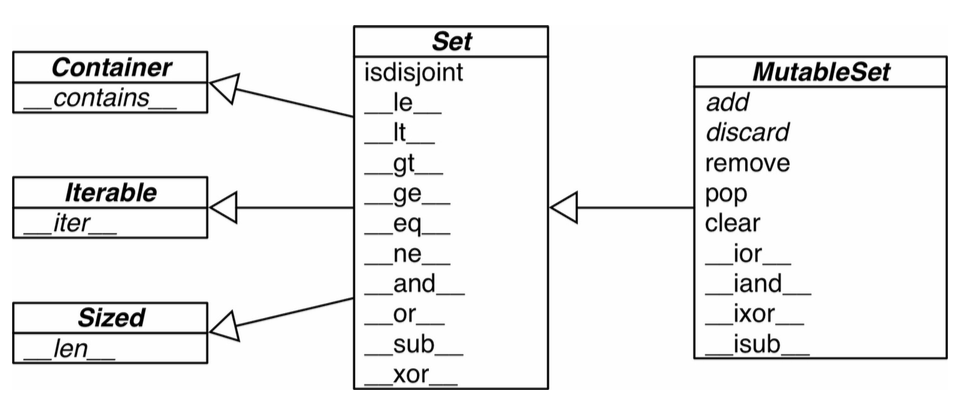
- 散列表实质上是一个 稀疏数组 ,其单元被称为表元,表元包含两个元素,一个是对键的引用,另一个是对值的引用
通过__hash__方法可以计算一个对应可散列对象的散列值,也就是说实现了__hash__方法的肯定是可散列对象,所有用户自定义的对象的散列值是通过id()来取的,所有用户自定义对象也是可散列的
在查询dict[key]的时候,会调用__hash__方法查询key的散列值,并根据最低几位值的偏移量(具体几位根据散列表的大小决定,取的那几位并非唯一的,有可能发生散列冲突,需要进一步进行处理,感觉和查字典好像啊,会不断产生散列冲突来找到那个值,真是太牛逼了,不过由于取的位数比较多,不像字典就那么26位所以发生散列冲突的概率比较小)来找到表元若找到为空则抛出异常,若找到则验证一下两个key是否相同,相同则返回对应的值
散列表键的次序取决于添加的顺序,如果添加顺序不一致,那么有可能因为发生散列冲突导致键的次序是不一样的,但是这个不影响
所以不能同时为字典进行迭代和添加,因为你不知道新增的键会出现在哪个位置
- python2中的str是字节序列(其实可以看作是ascii字符),只是在读取能操作的时候会隐式地转换为unicode字符序列,但是在python3中默认。所谓字节就是Byte,一个Byte等于8个位,有256种可能。
- 把码位转换为字节序列是编码,把字节序列转化为码位是解码
- 一般情况下对序列的切换返回的还是序列,对序列用__getitem__则会返回序列的元素,str是一个特例,两者都会返回序列本身,对于bytes对象,可以视作一个array,其中每个数字都是256以内的整数,bytes的打印如果在ascii表示范围内的则用ascii表示,否则用
\x开头的两个16进制数字来进行表示 - CPU分为大字节序和小字节序,所以多字节编码需要通过BOM指定大小字节序
- 处理文本的最佳实践是unicode三明治,即尽可能多地对unicode进行处理而非bytes,就像内置的文件open和write一样,open的时候需要指定encoding(没有的话用系统默认编码),write的时候会根据指定的encoding encode之后保存到文件,由于没有指定会用系统默认编码,因此有时候会出错,特别是windows这种非utf-8默认编码的环境下
多台设备下不能依赖默认编码,必须指定编码也就是encoding参数
- python当中的一等对象:
(1)在运行时创建(2)能赋值给变量或数据结构中的元素(3)能作为参数传给函数(4)能作为函数的返回结果归根结底这句话的意思就是函数也是我们通常所说的对象,函数是function类的实例
- 函数式编程有三个重要的函数map、filter和reduce,虽然有更好的替代品,但是需要了解一下,其中map接受一个数据处理的函数,用来对数据进行运算,而filter接受一个数据判断的函数,用来对对数据进行过滤,如果返回真值则保留,reduce则用来对一组数据进行重复地处理,先处理前两个,再处理返回值和后面一个数据,为什么要叫reduce,相当于一种降解,术语叫做”归约“
- lambda最合适的使用场景还是在高阶函数的参数列表当中,就如guiDownloaderPractice那个项目中command=xxx,这种地方用lambda会比较合适
- 语法糖:指计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。
其实python当中诸如装饰器什么的很多东西都是语法糖,正是因为有了这些语法糖python用来起才会那么舒服
- python当中的可调用对象:
(1)自定义的函数:包括用lambda和def定义的函数(2)内置函数:用c写的函数(3)内置方法:用c写的方法(4)方法(5)类:调用类的时候会调用类的__new__方法创建一个类的实例(6)类的实例:实现了__call__方法(7)生成器函数:调用之后返回一个生成器对象
- 创建保有内部状态的函数有两种方式,第一种是使用自定义类实例的__call__方法,还有一种则是使用闭包(其实还可以使用partial之类的工具函数,但本质上也是自定义类)
- __dict__属性用来存储赋予实例的 用户属性 (有些对象可能没有这个属性),而用dir()能够查询对象的所有属性
- 注意区别实例对象和对象,实例对象是类对象实例化之后生成的对象(__new__方法返回的)
- 函数如何实现闭包的呢?如果是普通的类实例对象作为函数,可以直接在一个属性中存储,而function类实例对象(函数)则是将自由变量存储在__closure__属性当中的
- 装饰器是闭包的一种特殊使用方式
def foo(func): def wrapper: print(1) func() return wrapper foo2 = foo(foo2) def foo2(): pass装饰器其实不一定会使用到自由变量,只是运用到了闭包的形式(函数里面套函数),它在闭包当中将其他操作与函数本身封装到了一起,注意这个封装,可以在函数开始前执行也可以在结束后执行。如果有自由变量的时候,这个自由变量会被存储到closure当中,实测closure只能针对狭义闭包(函数套函数)中的自由变量,而且如果闭包没有使用这个自由变量的话就不会被存储,函数对象当中存储了函数定义体当中定义的变量什么的信息,会在定义的时候就进行读取
- 对于装饰器的使用有两种方法,一种是前面这种将函数本身和其他逻辑封装到一起,另外一种则是不构建闭包,直接对函数进行操作,这种操作的话一般用来进行函数的注册。
- 还有一个问题,如果装饰器是封装下方定义的函数,那么为什么能在函数还未定义的时候就执行呢?有可能是会自动在下面找函数名
这个很好的解释了上面的问题:

- python可以通过从function实例的__code__属性当中查询到函数的参数表(含参数名),这有助于将对应的值传入函数。flask也许就是这样实现路由中的变量传输的。可以使用inspect模块的signature函数来构建一个Signature实例,来提取函数的键值对,这是一个不错的轮子
- python3的annotations挺有意思的,以后可以尝试使用一下
- python的type类型检测只能检测内置类型,所以还是推荐使用isinstance来对类型进行判断,并且可以用到collections.abc当中的一些 抽象基类
- 关于策略模式:
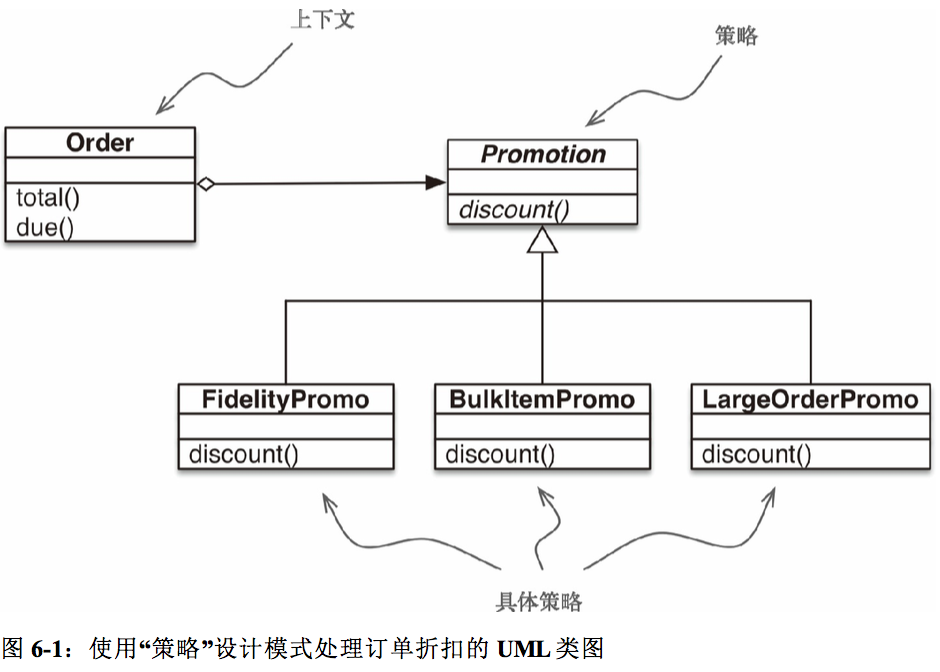
定义:定义一些算法,把它们一一封装起来,并且使得它们可以互相替换。
- 声明抽象基类可以通过子类化abc.ABC,抽象基类相当于定义一个接口,任何继承抽象基类的子类必须实现这些方法,否则无法被实例化
- 由于python当中函数是一等对象,因此没有必要去编写只有一个方法的类,直接用函数代替就行了,特别是在一些策略模式、命令模式当中(命令模式的宏命令可以通过定义一个有__call__方法的类来进行实现)
- 装饰器接受一个函数作为参数,其有两种处理手段一种是对输入的函数进行处理(即一般用来注册函数)另外一种是返回一个新的函数(即一般用来对函数进行执行前或执行后处理)
- 闭包可以用来存储历史值

闭包是一种函数,它会保留定义函数时存在的自由变量的绑定,这样调用函数时虽然定义作用域不可用了但是仍能使用那些绑定,可以说自由变量相当于函数对象的一个属性
- 可以使用nonlocal来将变量指定为自由变量,以便于在函数定义体内部对自由变量进行赋值操作(不然的话直接赋值相当于没有引用自由变量就不会绑定自由变量,这个和global的作用相似)
- 叠放装饰器

- python使用的是词法作用域而非动态作用域,这意味着python的函数会根据定义函数的环境计算自由变量(其实是定义函数的时候自由变量就已经指定了,但是还未计算出来),这个和闭包应该是具有一致性的(也许就是因为需要实现闭包才直接将自由变量绑定到函数上去)
- python的函数装饰器与”装饰器“设计模式当中所说的装饰器是略有不同的,如果要实现”装饰器“设计模式还是推荐使用类的方法(有什么好处呢?)
- isinstance并非通过实现的方法来进行判断(或者说对于非抽象基类不是, 至于抽象基类是不是还要再看看 ),实验了一下只有有明确继承关系的才能被认定为是这个instance
- 之前的认知是有误的,通过实例去改变类对象并不会改变被继承类的类对象,因为实例的类对象是存储在实例的dict当中的,如果实例当中没有才会去取类中的,有一个很好的例子:
source class test(): a = 1 test1 = test() test1.a = 2 del test1.a test1.a结果是1,这是因为我删掉test1本地的a之后本地dict(是否可以看作命名空间?)当中没有a了,那么就会去拿类的a
之后我再去del这个test1.a发现del不了,可能是因为权限问题? 这个等待解答
还有一个值得注意的点,test1.a这个东西其实是在赋值的时候创建在本地的,相当于函数里面创建了一个本地变量把全局变量覆盖了,其实是一套逻辑。这样来看dict里面存在的应该是当前定义域内的变量。 需要研究一下命名空间和定义域的分别,这块有些模糊
133. 继承自object类的对象的默认__eq__方法比较的是id,而内置类型大多都重载了__eq__方法使之更有意义,所以最好不要对自定义对象使用==操作符 135. 要分清变量和对象,变量相当于是对象的一个标签 136. 多数集合类型的对象(内部元素不统一)其内部变量保存的是对该对象的引用(应该可以是变量也可以单纯的引用,即id在cpython中也即内存地址),而不是对象本身,而str这种单一序列类型保存的则是连续内存当中的数据 137. 构造方法与切片操作都是浅复制,即只复制容器对象,容器对象里面的引用还是没变的(当然对str这种单一序列类型来说就不存在引不引用的问题,直接复制的就是值) 138. json.dumps的转化关系图

- 通过json.loads可以将json形式的bytes转化为json,因为content里面返回的是bytes并没有进行编码,所以最好是进行一下decode处理,如果自己不处理那么loads时会隐式地以utf-8 decode成str
- 遍历字典是在遍历字典的键
- python当中的|和&都是位运算
- 数据序列化是将结构化数据转换成允许共享或存储的格式,可恢复其原始结构的概念。 在某些情况下,数据序列化的第二个目的是将要序列化数据的大小最小化,从而使磁盘空间或带宽要求最小化。
python原生的数据序列化手段是pickle,json也是一种很好的数据序列化手段,不过pickle支持的类型肯定更多
- 这个小技巧我已经用到了,哈哈哈哈
注解
多重且混乱的循环依赖关系:假如在 furn.py 内的Table与Chair类需要 导入 workers.py 中的Carpenter类以回答类似 table.isdoneby() 的问题,并且Carpenter类需要引入Table和Chair类以回答 carpenter.whatdo() 这类问题,这就是一种循环依赖的情况。在这种情况下,你得借助一些不怎么靠谱的 小技巧,比如在方法或函数内部使用import语句。
- python当中可以使用copy来为任意对象做浅复制(只复制表层,如果存储的是引用也直接赋值过来)可以使用deepcopy来为任意对象做深复制(深复制能够优雅地处理循环引用)
- python的函数参数传递模式是共享传参(各个形式参数获得实参引用的副本),内部的参数其实是被传进来的变量的别名,因此如果在内部对引用的可变对象做修改的话会影响外部的对象,但无法对外部对象的标志(id)做修改,也就是说函数内部怎么操作都无法改变原变量与对象的对应关系,比如你往函数内传了一个a,然后赋值a=2并不会使外部的a发生改变(因为你里面的是形参呀)
- 在一个类定义的时候,其中的东西貌似就会先执行一遍(这个和单纯放在模块中一样,但不会做逻辑上的执行),所以如果__init__中使用了可变对象作为默认参数,那么这个对象就是确定的,因此才会出现幽灵bus的问题(问题就在于用了可变对象作为默认参数的话所有创建的实例都会引用这个对象,这样前面对于这个对象的操作就会干扰到后面创建的实例)

- 不管怎么样,处理可变对象作为参数的时候要三思而慎行,如果确实要修改,那么可以直接操作,如果不想修改,先复制之后再操作(复制要用list()之类的工厂函数,别直接用=号,那只是创建一个别名而已)
- del语句删除的只是变量(一种引用形式),而非对象,但是当del删除的是最后一个对这个对象的引用的时候,这个对象就会被当做垃圾回收(重新绑定对象也有一样的效果,所以我其实可以在tkinter当中直接重新绑定一个新对象)
- weakref模块是弱引用,弱引用不会改变对象的引用计数
- python控制台会将一个_变量绑定到一个最后一个不为none的对象上,这个会造成隐式的引用计数
- 对于引用计数还有一个需要注意的点是使用for循环往往也会创造一个引用计数,需要对其进行显式地删除
- weakvaluedictionary的作用是保存的都是弱引用,方便垃圾回收,但是并非所有对象都可以作为弱引用的目标(比如dict和list),对此可以使用其子类进行解决,但是int和tuple就连它们的实例都不行
- 每一个对象都有标识、值、类型,标识是id不会改变,值是对于可变类型来说是可变的,类型就是所属的类(可以看作是不变的)
open(‘test.txt’, ‘w’).write(‘1’)这种写法在python当中之所以没有问题是因为python通过引用计数销毁对象,所以不会存在内存泄露- 新增几种特殊方法的说明:
(1)``__str__`` :以便于用户理解的方式返回对象的字符串表示形式,会在交互解释器直接输入变量的时候调用(2)``__repr__`` :以便于开发者理解的方式返回对象的字符串表示形式,会在print的时候调用
- classmethod装饰器最常见的用途是用来备选构造方法(也就是可以调用这个方法来产生一个类实例),他的第一个参数始终是类本身
- format方法当中使用的是格式说明符(format_spec),其使用的语言规范叫做“格式规范微语言”
- python解释器会对双下划线开头的类变量做名称改写,但是有一个更好的方法是使用一个下划线开头来表明这个变量不该被访问(当然python解释器并不会进行改写处理)
- __slots__属性主要是用来节省内存的,不是用来做限制的,注意这一点,其原理是通过让解释器在元组中存储实例属性,而非在默认的__dict__当中,就像弱引用一样,一般的程序没必要去搞这个
- 这一段说到了实例属性对类属性的覆盖,就像sqlalchemy所做的那样

- 函数存储的貌似可以理解为自由变量的名称而非自由变量的别名,否则难以解释循环体当中构造的函数的自由变量都是同一个值
常见陷阱 — The Hitchhiker’s Guide to Python
可以看下这个,迟绑定闭包
注解
Python的闭包是 迟绑定 。 这意味着闭包中用到的变量的值,是在内部函数被调用时查询得到的。 这里,不论 任何 返回的函数是如何被调用的,i的值是调用时在周围作用域中查询到的。接着,循环完成,i的值最终变成了4。
文中提供的解决方案是使用默认参数(不知道对command那个场景是否适用)以及偏函数(这个相当于是一种能够保存对象的函数,和我所用的代理差不多,看来很多场景的轮子都是有的,没必要自己造)。前面一种方法应该用不了,因为不能设置参数,偏函数的方法倒是可以试一试,能否用看它的实现
- 序列类型的构造最好以可迭代对象为作为构造方法的参数,因为所有内置序列类型都是这样做的
- 使用iter工厂函数能够构建一个迭代器,不过需要的参数是什么呢?看下面
注解
- iter(object[, sentinel])
Return an iterator object. The first argument is interpreted very differently depending on the presence of the second argument. Without a second argument, object must be a collection object which supports the iteration protocol (the __iter__() method), or it must support the sequence protocol (the __getitem__() method with integer arguments starting at 0). If it does not support either of those protocols, TypeError is raised. If the second argument, sentinel, is given, then object must be a callable object. The iterator created in this case will call object with no arguments for each call to its __next__() method; if the value returned is equal to sentinel, StopIteration will be raised, otherwise the value will be returned.
See also Iterator Types.
One useful application of the second form of iter() is to read lines of a file until a certain line is reached. The following example reads a file until the readline() method returns an empty string:
- 可以对字符串类型调用find方法来找到某一个字符第一次出现的位置
- python的sequence类型和sequence protocol是完全不一样的,sequence protocol只有__len__和__getitem__两种方法,相当于是一种接口,文档中参数上写有Seq的表明这个参数需要符合sequence protocol,用各种protocol来代替接口也就是python鸭子类型的本质
对于protocol的定义:

- 如果想自己定义序列类型支持切片方法返回自定义的序列,可以通过在__getitem__中判断传进来的是否是slice对象,如果是的话,就利用类重新构造一个实例返回,只要给这个实例传一个使用了切片的可迭代对象参数就可以了,非常方便(这是因为内置序列类型都是会在__getitem__当中对slice进行处理的,我们只需要使用已经建好的轮子就可以,没必要自己去解析slice
- 想要获取某个自定义对象的类可以通过type函数来获取,其实就是返回
obj.__class__ - 使用抽象基类做isinstance可以使得检测更加灵活,难道是对于抽象基类只是检验其中的方法有没有实现么?
- 通过super可以在重载超类方法的情况下把部分任务交给超类的方法去做
- 如果实现了__getattr__方法,那么也需要实现__setattr__方法,防止对象行为不一致
- 所谓动态类型是指运行时检查类型,因为方法签名和变量没有静态类型信息
- 类的接口指的是类实现或继承的公开属性(的集合)

- 对于抽象基类,我目前需要用到的只有用isinstance进行判断,其他注册继承什么的暂时还用不到 python抽象基类abc - 简书

要继承抽象基类必须实现其所定义的抽象方法,因为如果你没有实现的话就会使用抽象方法,而抽象方法是不合规的,抽象基类当中并非全是抽象方法,因此只要覆盖抽象方法就行
抽象基类是用于封装框架所引入的一般性概念的
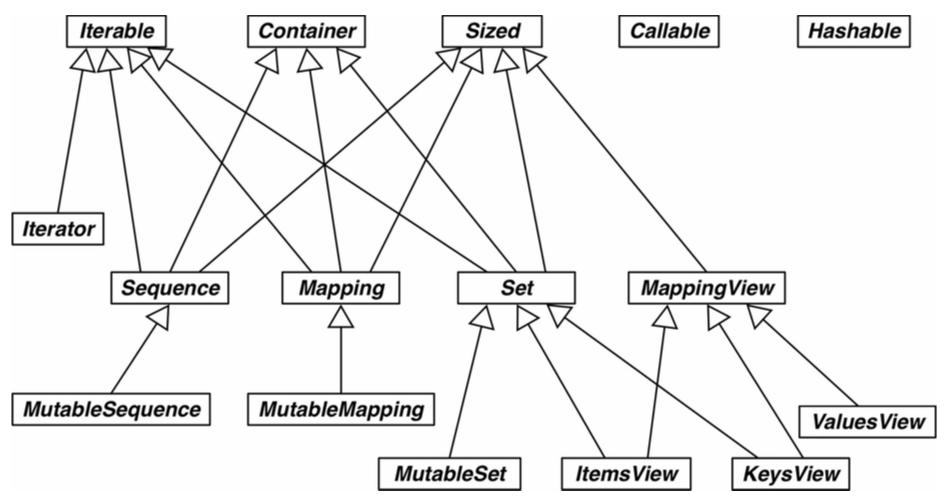
- 抽象基类大全
- 部分异常类的层次结构

- functool当中的wraps装饰器非常有用,可以使得被装饰的函数仍保持其原有的__doc__和__name__属性,但是装饰器当中的要return那个函数而不是执行那个函数。这个小技巧对于flask这种对取函数__name__作为endpoint的十分有用,平时用装饰器的时候最好也用一下。大致看了一下wraps的源码,其实就是把装饰器当中那个要return的函数的一些特殊属性替换一下而已,没什么特别的
- 如果要在类中使用装饰器,装饰器函数必须是外部定义的函数,即使是静态方法也是不可以的,这是因为装饰器在类定义的时候就会被执行
- 可以使用默认参数只计算一次这个坑来解决循环中建立函数变量不能存储的问题
- 返回多个值的话使用namedtuple而非普通tuple
- 内置类型的方法不会调用子类覆盖的特殊方法,所以不要去直接子类话内置类型,错误很多,而是应该去继承collections模块当中那些让用户来继承的类,比如UserDict,UserList这种
- 一个注意点,super()的替代方法:
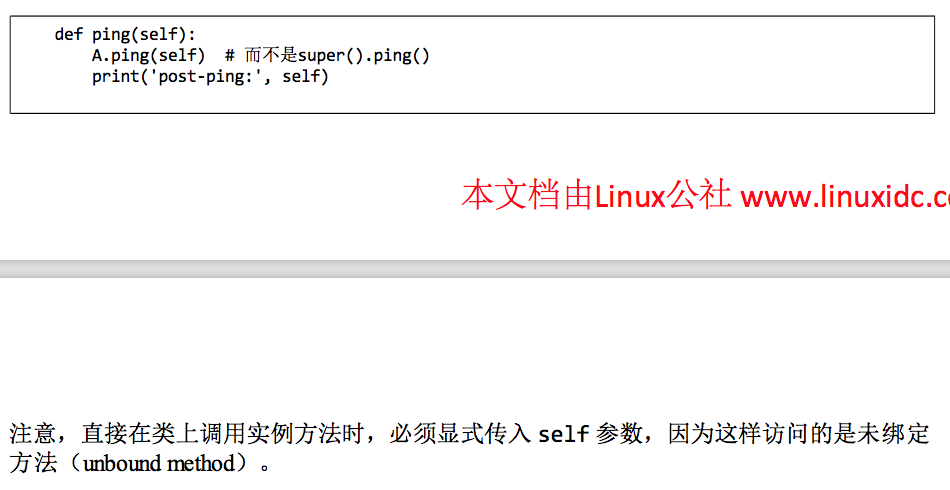
所谓unbound method意思的实例方法没有对应的实例绑定,即不是通过instance.进行t用的
- 多重继承如果超类的方法名重复的会,优先继承前面一个超类的方法,如果要调用其他超类的,那就需要的方法手动调用,可以通过查看__moro__属性查看方法解析顺序
- mix类亦即混入类,其不定义新类型只是打包方便,便于重用,当一个类只是为不相关的子类提供方法以进行方法重用的时候,应当定义这个类为混入类。有一个原则是混入类不能实例化,具体类则不能只继承混入类,并且混入类要在名称后面表明Mixin
- 多重继承的要点:
(1)最多只继承一个具体类,其他要么是混入类,要么是抽象基类(2)优先使用对象组合而非类继承,比如tkinter的widget没有必要继承grid,直接通过定义一个widget中的grid对象引用来调用grid就可以了(具体怎么实现我自己还要尝试一下,现在想得还不透彻)
- yiled from的作用解释


- 先在类中找特性再在实例中找属性,再在类中找属性

- 只有实现了
__set__的才是覆盖型的描述符

- 只实现了__set__方法的描述符的用途

- 注意

- 一定要注意,很多表达和操作符并非完全等同于特殊方法,比如
a + b,并不完全等同于a.add(b),而是有一系列的执行逻辑在里面,所以不能将操作符等效于特殊方法来看待 - virtualenv的原理其实就是直接在PATH里面加上虚拟环境的bin路径,这样使用python的时候就会直接使用该路径下的python了
- Lock的基本工作原理:只能同时被一个线程acquire,其他的都会阻塞
- rich comparison:Python对象比较的一种新的机制,允许返回值不仅仅是-1,0或者1。其动机是为了解决较为复杂的比较,例如x<y<z,再比如想x,y都是array,做比较的结果
- 由于抽象基类不能实例化,因此也就不能拥有成员变量,这样的话说明抽象基类更加适合用在接口层面。python 可以直接获取成员变量,这就导致python的接口用起来没有那么舒服啊,你不能为接口定义一个变量(其实是可以的,定义的构造方法也是可以被继承的)
- python当中既然不需要多态那为什么要进行继承呢?我觉得主要的用途还是结构化代码,提高代码的复用效率
- python的抽象基类的作用是用来做类型检查,因为鸭子类型毕竟有时候是不太靠谱的
- python最外层init所在目录才能称之为包啊,底层要从头开始调用,也就是说你如果是一个二级目录的话要从包名开始进行调用
- 不要在项目群层级上开pycharm,这会导致import中的提示出现错误,因为默认会以你所在的目录打开进行文件操作
- python import的路径是按照main的路径为基准的,而文件位置什么的才是按照调用位置为基准的。似乎是这样,这个还需要进行验证
- 一个线程只能启动一次
- 写python的时候不要乱引同目录下的文件,只引包中的文件。同目录文件其实也是可以的,因为import的位置是按照运行文件的目录定的,然而ide下的代码提示是根据项目所在目录来的,所以最好的方式是项目执行文件在项目目录下,然后整个应用程序包在同级目录下,或者是整个项目是一个包。感觉前一种方式用起来更加舒服一些。
- 关于python多线程的退出:线程不使用死循环,而使用条件循环https://www.zhihu.com/question/49830386