标准库¶
文本处理¶
string(2)¶
一个与字符串有关的工具库,包含一些常用的字符串操作函数,其中string.Formatter这个类与str的format方法类似
一,字符串常量¶
包含诸多常用的的字符串常量,使用十分方便
- string.ascii_letters:包含大小写
- string.ascii_lowercase
- string.ascii_uppercase
- string.digits:十进制数字
- string.hexdigits:十六进制数字
- string.octdigits:八进制数字
- string.punctuation:标点符号
- string.printable:digits、ascii_letters、punctuation和whitespace的合集
- string.whitespace:space、tab、return等不可见的字符
二,格式化字符串¶
有一个Formatter类,其提供了一系列格式化字符串的方法(为什么不用函数来做,用类有什么好处么?答:好处就是可以通过继承重写类方法来自定义解析方式),主要的方法是format,其使用和内建的format方法一致
三,格式化字符串语法的介绍¶
这种语法叫做format specification mini-language,具体的语法内容就先不展开了,有时间的话再系统性地学习一下吧
四,字符串模板¶

re(3)¶
正则表达式
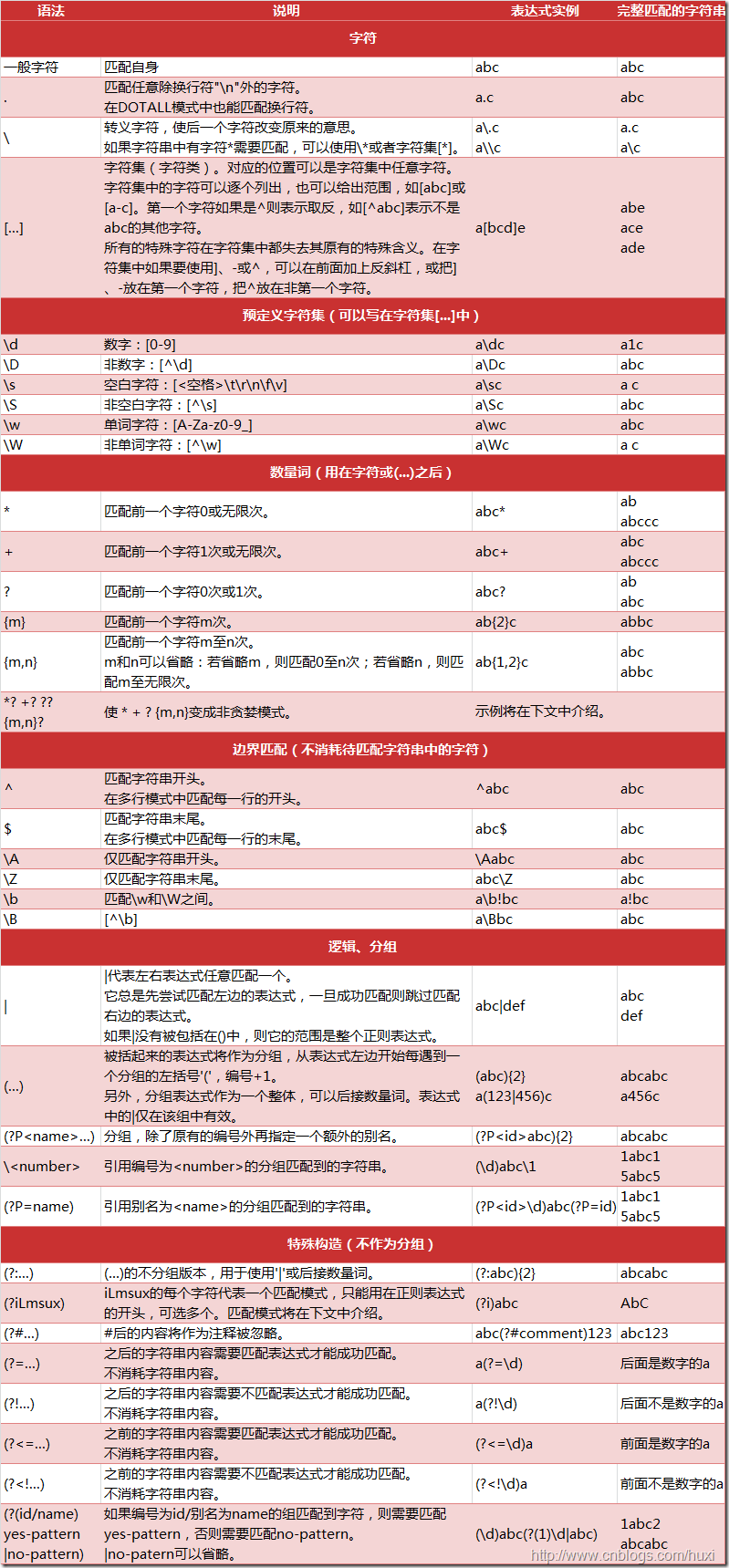
二,模块内容¶
- re.compile:用来封装正则表达式模式,可用来进行重用
- re.ASCII:flag,只进行ascii字符匹配而非全unicode匹配
- re.DEBUG:flag,显示debug信息
- re.IGNORECASE:flag,忽略大小写
- re.LOCALE:flag,不懂
- re.MULTILINE:flag,^和$能够匹配行头和行尾
- re.DOTALL:.能够匹配换行符
- re.VERBOSE:能够给正则表达式加注释
- re.search:如果找到就返回一个match object,否则返回None,注意只会找一个
- re.match:从字符串的头部开始找,如果匹配则返回一个match object,否则返回None,记住是从头部开始,match object中包含所有匹配
- re.fullmatch:要整段都匹配才算匹配成功
- re.split:切割str,返回一个列表
- re.findall:同search类似,不过会返回全部的字符串列表,而非match object
- re.finditer:返回一个生成match object的迭代器对象
- re.sub:用于替换字符串
- re.subn:和sub类似,不过会返回一个包含结果字符串和替换次数的元组
- re.escape:转义所有非ASCII letters
- re.purge:清理正则表达式缓存(干吗用的??)
- re.error:正则表达式异常
三,正则表达对象regex¶
re.compile的返回结果,其方法与模块级函数类似
四,Match object¶
- match做判断的时候总是为True,这是估计是因为某个特殊方法把,没查出来
- match.__getitem__可以取出匹配的字符串
- 还有一些乱七八糟的方法,先不深入研究了
注意事项¶
.默认情况下不能匹配换行符,只有在flag=DOTALL模式下才能匹配换行符r'xxx'中的r代表的是raw string,在raw string当中字符串不会被转义,相当于r'\n'代表的就是反斜杠+n,而非换行符,在使用正则表达式的时候通常需要使用raw string,虽然我看不出来不使用raw string会产生什么影响,目前来看结果似乎是一致的(因为你不转义正则表达式就会帮你转义,不对,还是有区别的,对于\\\\这种的就会出现转义两次的情况),因此必须使用raw string- 正则表达式可以直接用来匹配bytes,并非只能用于string
数据类型¶
datetime(2)¶
提供三种基本的时间类型:date, time和datetime,以及一系列对应的方法
存在两种时间对象,分别为"naive"和"aware",前者没有包含足够多信息但很简单,后者包含很多信息单比较复杂,实际上区别就在于tzinfo(时区)属性是否为空
一,常量¶
- datetime.MINYEAR:允许的最小年份为1
- datetime.MAXYEAR:允许的最大年份为2
二,对象类型¶
- datetime.date:naive date类型,属性为year,month和day
- datetime.time:时间类型,属性为minute,second,microsecond和tzinfo
- datetime.datetime:时间+日期,属性为时间和日期属性的结合
- datetime.timedelta:date、time或者datetime之间的时间间隔
- datetime.tzinfo:时区信息的抽象类
- datetime.timezone:继承了tzinfo,针对UTC时间
三,timedelta Objects¶
没啥好说的,支持一些基本的数学运算,加减乘除,还有取余取负等等都支持
四,date Objects¶
几个类方法:
- date.today():返回当天日期(date)
- date.fromtimestamp():根据时间戳返回一个日期(date)
- date.fromordinal():根据proleptic Gregorian ordinal返回一个日期(date)
五,datetime Objects¶
几个类方法:
- datetime.today():返回当天日期(datetime)
- datetime.now():返回当天日期,可以选择tz
- datetime.utcnow():返回的是UTC date
- datetime.fromtimestamp()
- datetime.utcfromtimestamp()
- datetime.fromordinal()
- datetime.combine():用于将date和time合并为datetime
- datetime.strptime()
六,time Objects¶
没啥好说的
七,tzinfo Objects¶
关于时区的,太复杂了不去管它
八,timezone Objects¶
和第七条差不太多
collections(2)¶
在python基本容器类型之外又提供多种容器数据类型,包括
- namedtuple
- deque
- ChainMap
- Counter
- OrderdDict
- defaultdict
- UserDict
- UserList
- UserString
一,ChainMap Objects¶
ChainMap主要用来将一系列的映射类型对象进行组合成一个可更新的view
属性:
- maps:一个包含所有映射的list
- new_child(m=None):返回一个新的ChainMap对象包含一个新的map,并且这个map排在list的最前面
- parents():返回一个新的ChainMap,不包含第一个map
注意d['x']返回的是Chain里面第一个键所对应的值,同样设值的时候设的也是第一个键所对应的值
用法上其实和普通的Map类型差不太多,相当于是把多个Map合并成一个Map来使用
二,Counter Objects¶
Counter是dict的子类,用来计算hashable对象的个数
属性:
- elments():返回一个迭代器,产生对象,有几个就产生几次
- most_common([n]):返回个数最多的n个对象的列表,对象和次数放在一个元组里面
- subtract():在原有的Counter中去除元素
- fromkeys():
- update([iterable-or-mapping]):增加元素的计数
Counter对象还支持加减法等操作
三,deque Objects¶
deque亦即双端队列,构造时通过collections.deque([iterable[, maxlen]])返回
deque提供线程安全的append和pop方法,即使用多线程进行操作时不用刻意为其加锁(是么?答:是的,deque的线程安全实现方式看 这里 )
deque的append和pop方法是非常高效的,其时间复杂度为O(1),这是其相较于list的优势所在
如果限定了了deque的maximum length,一旦增加full了,从一个头增加一个数据就会从另一头丢弃一个数据,非常适合用来建立数据池(池的概念就是容量是有最大值限定以防止程序的崩溃)
属性:
- append()
- appendleft()
- clear():移除所有元素
- copy():返回一个当前deque的浅拷贝
- count(x):计算等于x的元素数量
- extend(iterable)
- extendleft
- index(x[, start[, stop]]):返回x的index
- insert(i, x):在i位置插入x
- pop()
- popleft()
- remove(value):移除第一个符合的value
- reverse()
- rotate(n):往右旋转n steps
- maxlen
四,defaultdict Objects¶
可以设定默认值的字典,其初始化方法的第一个参数是default_factory,相当于是一个返回默认值的函数/方法,通常可以使用内置的str(),int()等
defaultdict的原理是改写了__missing__方法,这样在__getitem__取不到值的时候能够调用__missing__方法来设定默认值
五,namedtuple Objects¶
namdtuple(typename, fields_names)工厂函数能够创建一个名为typename的tuple的子类,该子类可以用来创建一个具有field name的tuple子类,既可以通过序号也可以通过field name来调用tuple当中的元素
六,OrderedDict Objects¶
和普通的dict一样但是是有序的,会记住插入key的顺序
collections.abc(2)¶
提供容器类型的抽象基类,用于接口的方便测试和定义


关于view的定义:The objects returned by dict.keys(), dict.values() and dict.items() are view objects. They provide a dynamic view on the dictionary’s entries, which means that when the dictionary changes, the view reflects these changes.
array(1)¶
提供数组类型,用于数值,array和list差不太多,但是所能存储的数据类型是受限制的,仅能存储int, unicode character和float三种python类型,但是底层似乎是通过C类型进行存储的(感觉过于底层了,不是很了解)
array的用途主要是数据型操作比如矩阵乘法等的运算(暂时还用不到不往深层次了解了)
weakref(1)¶
python基础类型的弱引用形式,weak references的主要作用是针对存储大量数据的映射类型,因为映射类型如果存储的是强引用,那么只能通过显式地删除该映射,才能彻底地删除这些数据,但是存储的是弱引用(即映射中键对应的值是弱引用而非强引用),只要在其他地方回收了这些数据,该映射当中的键就会自动删除。
额外要要注意的一点是weakValueDictionary不能作用于基本类型,因为这些类型是无法创建弱引用的
一些常用的类介绍一下
- WeakValueDictionary:值是弱引用,如果键对应的值引用的对象没有其他强引用就会导致键值对去除
- WeakSet:值是弱引用,如果值引用的对象没有其他强引用就会导致值去除
- WeakMethod:方法对象的弱引用,需要结合方法与函数的区别加以理解
- finalize:会在其对应的obj被回收的时候调用
- ref:建立一个对象的弱引用,本质上其实是一个代理
copy(1)¶
提供copy和deepcopy两种函数来为对象创建浅拷贝和深拷贝,并且定义了一个异常copy.error
数字处理¶
math(1)¶
提供用于数学运算的函数,暂时用不太上
random(1)¶
提供各种伪随机数生成器
其中提供的绝大部分函数都是基于一个random()函数,它会生成一个0-1之间的随机浮点数(伪随机),随机数生成的底层实现是线程安全的。该模块提供的函数其实是绑定了random.Random实例的方法(所谓方法其实就是有对象绑定的函数),具体的机制是怎么实现的没有细说,之后再慢慢了解吧
一,Bookkeeping functions¶
- random.seed:初始化一个随机数生成器,默认使用系统时间生成随机数,当时就感觉这个函数的调用莫名其妙的,原来是有一个隐藏的Random实例在中间起作用
二,Functions for integers¶
- random.randrange():返回一个范围内的integer
- random.randint():等价于randrange(a, b+1)
三,Functions for sequences¶
- random.choice(seq):随机返回序列中的一个元素
- random.choices():Return a k sized list of elements chosen from the population with replacement. If the population is empty, raises IndexError.
- random.shuffle():将一个序列进行洗牌
- random.sample():从一个population set/sequence当中取出长度为k的list
四,Real-valued distributions¶
不懂什么是real-valued,是实数?
decimal(1)¶
提供比float更加精确的小数数据类型
Decimal “is based on a floating-point model which was designed with people in mind, and necessarily has a paramount guiding principle – computers must provide an arithmetic that works in the same way as the arithmetic that people learn at school.” – excerpt from the decimal arithmetic specification.
这段话说得不错,float和java当中的float以及double都不太好用,从使用的角度来看还是直接用decimal比较合适,反正之后需要用到精确计算的地方都使用decimal就可以了
函数式编程¶
itertools(2)¶
提供多种迭代器构建工具
一,infinite Iterators¶
- count(start,[step]):从start开始迭代
- cycle(p):循环迭代一个序列p
- repeat(elem[,n]):重复elem无限次或n次
二,Iterators terminating on the shortest input sequence¶
- accumulate():将一个序列的前n个数依次累加
- chain():连接两个序列,依次取出合并序列当中的元素
- chain.from_iterable():将一个iterable当中的元素相连,依次取出合并序列当中的元素
- compress():利用过滤器压缩序列,并迭代
- dropwhile():利用过滤器压缩序列的另一种形式,并迭代
- filterfalse():利用过滤器压缩序列的又一种形式,并迭代
- groupby()
- islice():将已有序列切片,并迭代
- starmap():一次将序列中的元素作为参数传入函数并计算结果值
- takewhile():依次迭代序列,判断失败时停止
- tee()
- zip_logest():将两个序列的元素相组合
三,Combinatoric generators¶
- product()
- permutations()
- combinations()
- combinations_with_replacement()
对我来说用处不是太大,不管理
functools(2)¶
提供多种高等函数(操作与函数本身或者返回函数的函数)
- functools.cmp_to_key():将python2当中的老式比较(compare)函数转换成key function,所谓key function就是a callable that returns a value used for sorting or ordering,也就是返回一个用来比较的值的函数
- @functools.lru_cache():这个不太懂
- @functools.total_ordering:用于辅助定义了rich comparison method类的构建
- functools.partial():返回一个partial object,这是一个可调用对象,相当于对某个函数封装了一些固定的参数
- class functools.partialmethod():用来对descriptor对象进行封装,返回的是一个descriptor对象(函数本身就是descriptor对象)
- functools.reduce():归约函数
- @functools.singledispatch():将一个函数转换成single-dispatch generic function,这个generic function从含义上看和java的方法重载挺像的
- functools.update_wrapper():wraps装饰器的函数调用形式,作用相同
- @functools.wraps():改变wrapper函数的元数据,使其与被wrap的函数相同
- partial Objects: partial函数返回的对象
数据持久化¶
pickle(2)¶
用于序列化和反序列化python对象
一,安全性问题¶
The pickle module is not secure against erroneous or maliciously constructed data. Never unpickle data received from an untrusted or unauthenticated source.
二,与json相比较¶
- json是文本形式的具有可读性,而pickle是二进制形式的
- json适用范围广,pickle只适用于python
- json只能用来表示python的一些基础类型,不能用于复杂的数据结构
三,模块接口¶
- 使用dumps将进行序列化,使用loads进行反序列化,如果需要更加强大的功能的话需要创建Pickler或者Unpickler对象
- pickle.dump():序列化至文件
- pickle.dumps():返回序列化后的bytes
- pickle.load():从文件进行反序列化
- pickle.loads():从bytes进行反序列化
- class pickle.Pickler():深度的以后再说
- class pickle.Unpickler():深度的以后再说
四,What can be pickled and unpickled?¶
可以被pickle的类型,简单看一下就好了
- None, True, and False
- integers, floating point numbers, complex numbers
- strings, bytes, bytearrays
- tuples, lists, sets, and dictionaries containing only picklable objects
- functions defined at the top level of a module (using def, not lambda)
- built-in functions defined at the top level of a module
- classes that are defined at the top level of a module
- instances of such classes whose __dict__ or the result of calling __getstate__() is picklable (see section Pickling Class Instances for details).
五,更加深入的内容¶
下回详解
shelve(2)¶
提供一个名为shelf的dictionary-lile对象,其用于python对象的存储,相当于是一个用于存储python对象的数据库,能够持久化存储数据,其底层还是通过pickle来实现的
一,接口简介¶
- shelve.open():打开一个持久化存储的字典,返回一个Shelf对象
- Shelf.sync():将缓存当中的数据同步到持久化存储的文件当中
- Shelf.close():关闭持久化存储,同时进行数据同步
二,限制¶
- 不支持并发读写,但是单纯读的话是线程安全的
sqlite3(1)¶
提供对于SQLite(一个轻量级的数据库)的操作
一,简单用法¶
- 首先建立一个数据库连接以代表数据库
conn = sqlite3.connect('example.db') - 其次创建一个cursor对象来执行SQL命令
c = conn.cursor()
csv(1)¶
提供对于CSV(Comma Separated Values)格式的操作
简单介绍¶
- csv.reader():打开一个csv文件,返回一个reader对象
- csv.writer():打开一个csv文件,返回一个writer对象
- class Dialect:这里的dialect是专业用语的意思,相当于csv文件的一套专业用语体系。To make it easier to specify the format of input and output records, specific formatting parameters are grouped together into dialects.
操作系统¶
os(2)¶
操作系统相关
一,Process Parameters¶
- os.ctermid():返回与控制终端相关的文件
- os.environ():返回一个与环境变量相关的字典
- os.environb():bytes版的environ
- os.getcwd():返回当前工作目录
- os.fsencode():将文件名用filesystem的编码方式进行编码
- os.fsdecode():反过来
- os.fspath():返回一个path对象的表示
- class os.PathLike:表示文件系统路径的对象的抽象类,有一个__fspath__方法
- os.getenv():返回对应的环境变量,若存在
- os.getenvb():bytes版getenv
- os.get_exec_path():返回系统可执行程序的查找列表
- os.getegid():关于各种id,见 这里
- os.geteuid()
- os.getid()
- os.getgrouplist()
- os.getgroups()
- os.getlogin():返回进程控制终端的登陆者的用户名
- os.getpgid():返回进程组id和进程id
- os.getpgrp()
- os.getpid():返回pid
- os.getppid():返回父进程的pid
- 后面乱七八糟的函数实在是太多了,反正跟系统相关,需要用到的肯定是有的
二,文件描述符(File Descripter)操作¶
- 文件描述符其实就是一些当前进程打开的文件,用一些整数指代,0、1、2这三个文件描述符通常被标准输入、标准输出和标准错误这三个文件使用,在unix平台当中,sockets和管道也是通过文件描述符来指代的
- os.close():关闭对应文件
- os.closerange():关闭一个range内的文件
- os.device_encoding():返回设备的编码方式,mac下为utf-8
- os.dup():返回一个对于文件描述符的拷贝
- os.fchmod():改变文件的mode
- os.fchown():改变文件的所有者和用户组
- os.fpathconf():返回系统配置
- os.fstat():获取文件描述符的状态
- 还有很多,不详细说了
三,文件和目录¶
四,进程管理¶
os.path(2)¶
文件操作相关的函数,都是通过文件名进行操作的
与os中的文件操作的主要区别在于,os中操作对象主要是fd(file descripter),而os.path当中的操作对象则是path
sys(2)¶
python解释器相关
并发¶
threading(3)¶
在底层_thread模块的基础上构建的更高层级的多线程模块
queue(2)¶
提供用于多线程的安全数据交换的队列
concurrent.futures(2)¶
提供用于多线程和多进程的高层级接口,ThreadPoolExecutor和ProcessPoolExecutor都继承了相同的接口